
《疯狂JAVA讲义》学习笔记
写过很多java代码,甚至写过不大不小的spring项目,但始终感觉自己的java基础有所欠缺,就连lambda表达式都看不明白,决定静下心来,花大量时间把这本900页的《疯狂JAVA》彻底详细的学习一遍。
本篇博客将每日持续更新……
JAVA语言概述与开发环境
编译Java程序
设置class文件编译路径:
javac -d destdir javaFile
当前路径:
javac -d . HelloWorld.java
或
javac HelloWorld.java
使用-d可以生成包相对应的文件结构,因此,推荐编译Java文件的时候总是使用-d选项。
运行Java程序
java HelloWorld(class字节码文件名)
java命令将从CLASSPATH环境变量下寻找java类,一般都会配置包含(.),也就是当前路径
jdk1.4以前的版本必须配置CLASSPATH jdk1.5以上的版本可以不配置CLASSPATH,一旦配置,JRE将会按该环境变量指定的路径来搜索JAVA类。这意味着如果CLASSPATH环境变量中不包含(.),也就是没有包含当前路径,JRE不会在当前路径下搜索JAVA类
除此之外,编译和运行Java程序还需要JDK的lib路径下的dt.jar和tools.jar文件中的Java类,因此还需要把这两个文件添加到CLASSPATH环境变量中。(JDK11的lib目录已经不再包含dt.jar和tools.jar)
CLASSPATH:.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;
指定jre搜索java类的路径:
java -classpath dir1;dir2;dir3;....;dirN Java类
等同于:
java -cp dir1;dir2;dir3;....;dirN Java类
如果在运行JAVA程序的时候指定了-classpath选项的值,JRE将严格按-classpath选项所指定的路径来搜索Java类,而不会在当前路径下搜索JAVA类,CLASSPATH环境变量所指定的搜索路径也不再有效
如果希望CLASSPATH环境变量指定的路径和自定义路径同时生效,则可以按如下格式来运行Java程序
java -classpath %CLASSPATH%;.;dir1;dir2;dir3;....;dirN Java类
Java程序的基本规则
最简单的Java程序
class Test
{
}
这是一个绝对正确的Java程序,只是没有入口,所以用java命令运行这个Test类的时候会报错(在类Test中找不到main方法,请将main方法定义为 public static void mian(String []args)
java程序的源文件名是可以任意的,但有一种情况例外:如果java程序源代码里定义了一个public类,则该源文件的主文件名必须与该public类的类名相同
Crazyit.java
class Dog{
}
class Item{
}
class Category{
}
上面程序使用同一个源文件定义了3个独立的类:Dog、Item、Category。使用javac命令编译该Java程序,将会生成3个.class文件,每个类对应一个.class文件
交互式工具:jshell
从JDK9开始,JDK内置了一个强大的交互式工具:jshell。他是一个REPL(read-eval-print Loop)工具。
jshell在bin目录里,如果已经配置了PATH,直接cmd输入jshell就可以进入jshell交互模式
/help 查看帮助
/exit 退出
/edit 编辑用户输入的第几行代码,比如/edit 2 会启动一个文本编辑界面让用户来编辑第2条源代码
/save 保存用户输入的源代码
/vars 列出用户定义的所有变量
/methods 列出用户定义的全部方法
/types 列出用户定义的全部类型
数据类型和运算符
Java关键字
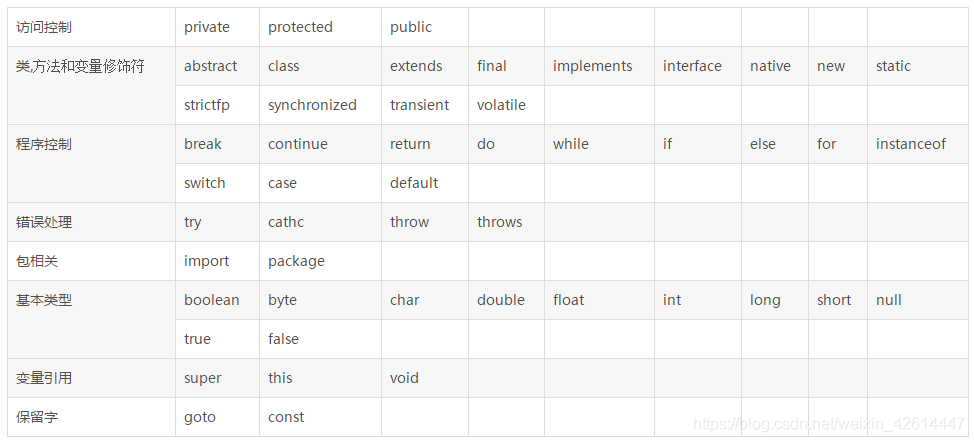
enum是从Java5新增的关键字,用于定义一个枚举,而goto和const这两个关键字也被称为保留字(reserved word),Java现在还未使用这两个关键字,但可能在未来的Java版本中使用这两个关键字;不仅如此,Java还提供了3个特殊的直接量(literal):true、false和 null;Java语言的标识符也不能使用这三个特殊的直接量。
从Java10引入了var并不是关键字,它相当于一个可变的类型名,因此var依然可作为标识符。
位运算
1.位运算概述
从现代计算机中所有的数据二进制的形式存储在设备中。即 0、1 两种状态,计算机对二进制数据进行的运算(+、-、*、/)都是叫位运算,即将符号位共同参与运算的运算。
口说无凭,举一个简单的例子来看下 CPU 是如何进行计算的,比如这行代码:
int a = 35;
int b = 47;
int c = a + b;
计算两个数的和,因为在计算机中都是以二进制来进行运算,所以上面我们所给的 int 变量会在机器内部先转换为二进制在进行相加:
35: 0 0 1 0 0 0 1 1
47: 0 0 1 0 1 1 1 1
————————————————————
82: 0 1 0 1 0 0 1 0
所以,相比在代码中直接使用(+、-、*、/)运算符,合理的运用位运算更能显著提高代码在机器上的执行效率。
2.位运算概览
| 符号 | 描述 | 运算规则 |
|---|---|---|
| & | 与 | 两个位都为1时,结果才为1 |
| | | 或 | 两个位都为0时,结果才为0 |
| ^ | 异或 | 两个位相同为0,相异为1 |
| ~ | 取反 | 0变1,1变0 |
| << | 左移 | 各二进位全部左移若干位,高位丢弃,低位补0 |
| >> | 右移 | 各二进位全部右移若干位,对无符号数,高位补0,有符号数,各编译器处理方法不一样,有的补符号位(算术右移),有的补0(逻辑右移) |
3.按位与运算符
定义:参加运算的两个数据,按二进制位进行"与"运算。
运算规则:
0&0=0 0&1=0 1&0=0 1&1=1
总结:两位同时为1,结果才为1,否则结果为0。
例如:3&5 即 0000 0011& 0000 0101 = 0000 0001,因此 3&5 的值得1。
注意:负数按补码形式参加按位与运算。
与运算的用途:
1)清零
如果想将一个单元清零,即使其全部二进制位为0,只要与一个各位都为零的数值相与,结果为零。
2)取一个数的指定位
比如取数 X=1010 1110 的低4位,只需要另找一个数Y,令Y的低4位为1,其余位为0,即Y=0000 1111,然后将X与Y进行按位与运算(X&Y=0000 1110)即可得到X的指定位。
3)判断奇偶
只要根据最未位是0还是1来决定,为0就是偶数,为1就是奇数。因此可以用if ((a & 1) == 0)代替if (a % 2 == 0)来判断a是不是偶数。
4.按位或运算符(|)
定义:参加运算的两个对象,按二进制位进行"或"运算。
运算规则:
0|0=0 0|1=1 1|0=1 1|1=1
总结:参加运算的两个对象只要有一个为1,其值为1。
例如:3|5即 0000 0011| 0000 0101 = 0000 0111,因此,3|5的值得7。
注意:负数按补码形式参加按位或运算。
或运算的用途:
1)常用来对一个数据的某些位设置为1
比如将数 X=1010 1110 的低4位设置为1,只需要另找一个数Y,令Y的低4位为1,其余位为0,即Y=0000 1111,然后将X与Y进行按位或运算(X|Y=1010 1111)即可得到。
5.异或运算符(^)
定义:参加运算的两个数据,按二进制位进行"异或"运算。
运算规则:
0^0=0 0^1=1 1^0=1 1^1=0
总结:参加运算的两个对象,如果两个相应位相同为0,相异为1。
异或的几条性质:
- 1、交换律
- 2、结合律 (a^b)^c == a^(b^c)
- 3、对于任何数x,都有 x^x=0,x^0=x
- 4、自反性: a^b^b=a^0=a;
异或运算的用途:
1)翻转指定位
比如将数 X=1010 1110 的低4位进行翻转,只需要另找一个数Y,令Y的低4位为1,其余位为0,即Y=0000 1111,然后将X与Y进行异或运算(X^Y=1010 0001)即可得到。
2)与0相异或值不变
例如:1010 1110 ^ 0000 0000 = 1010 1110
3)交换两个数
实例
void Swap(int &a, int &b){ if (a != b){ a ^= b; b ^= a; a ^= b; } }
6.取反运算符 (~)
定义:参加运算的一个数据,按二进制进行"取反"运算。
运算规则:
~1=0
~0=1
总结:对一个二进制数按位取反,即将0变1,1变0。
异或运算的用途:
1)使一个数的最低位为零
使a的最低位为0,可以表示为:a & ~1。~1的值为 1111 1111 1111 1110,再按"与"运算,最低位一定为0。因为" ~"运算符的优先级比算术运算符、关系运算符、逻辑运算符和其他运算符都高。
7.左移运算符(<<)
定义:将一个运算对象的各二进制位全部左移若干位(左边的二进制位丢弃,右边补0)。
设 a=1010 1110,a = a<< 2 将a的二进制位左移2位、右补0,即得a=1011 1000。
若左移时舍弃的高位不包含1,则每左移一位,相当于该数乘以2。
8.右移运算符(>>)
定义:将一个数的各二进制位全部右移若干位,正数左补0,负数左补1,右边丢弃。
例如:a=a>>2 将a的二进制位右移2位,左补0 或者 左补1得看被移数是正还是负。
操作数每右移一位,相当于该数除以2。
10.复合赋值运算符
位运算符与赋值运算符结合,组成新的复合赋值运算符,它们是:
&= 例:a&=b 相当于 a=a&b
|= 例:a|=b 相当于 a=a|b
>>= 例:a>>=b 相当于 a=a>>b
<<= 例:a<<=b 相当于 a=a<<b
^= 例:a^=b 相当于 a=a^b
运算规则:和前面讲的复合赋值运算符的运算规则相似。
不同长度的数据进行位运算:如果两个不同长度的数据进行位运算时,系统会将二者按右端对齐,然后进行位运算。
以"与运算"为例说明如下:我们知道在C语言中long型占4个字节,int型占2个字节,如果一个long型数据与一个int型数据进行"与运算",右端对齐后,左边不足的位依下面三种情况补足,
1)如果整型数据为正数,左边补16个0。
2)如果整型数据为负数,左边补16个1。
3)如果整形数据为无符号数,左边也补16个0。
如:long a=123;int b=1;计算a& b。
如:long a=123;int b=-1;计算a& b。
如:long a=123;unsigned intb=1;计算a & b。
基本数据类型
整数
byte: 一个byte类型整数在内存里占8位,表数范围是-128(-2^7^)~127(2^7^-1)
short: 一个short类型整数在内存里占16位,表数范围是-32768(-2^15^)~32767(2^15^-1)
int: 一个int类型整数在内存里占32位,表数范围是-2147483648(-2^31^)~2147483647(2^31^-1)
long: 一个long类型整数在内存里占64位,表数范围是-2^63^~2^63^-1
//下面代码是正确的,系统会自动把56当成byte类型处理
byte a = 56;
/*
下面代码是错误的,系统不会把9999999999999当成long类型处理
所以超出int的表数范围,从而引起错误
*/
// long bigValue = 999999999999999;
// 下面代码是正确的,在巨大的整数值后使用L后缀,强制使用long类型
long bigValue2 = 92222321321412321321L;
Java中整数值有4种表示方式:十进制、二进制、八进制和十六进制,其中二进制的整数以0b或0B开头;八进制的整数以0开头;十六进制的整数以0x或者0X开头,其中10~15分明以a~f(此处的a~f不区分大小写)来表示
//以0开头的整数值是八进制的整数
int octalValue = 013;
//以 0x 或 0X 开头的整数值是十六进制的整数
int hexValue1 = 0x13;
int hexValue2 = 0xaF;
在某些时候,程序需要直接使用二进制整数,二进制整数更真实,更能表达整数在内存中的存在形式。不仅如此,有些程序(尤其在开发一些游戏时)使用二进制整数还会更便捷。
从Java7开始新增了对二进制整数的支持,二进制的整数以0b或者0B开头,程序片段如下:
//定义两个8位的二进制整数
int binVal1 = 0b11010100;
byte binVal2 = 0B01101001;
//定义一个32位的二进制整数,最高位是符号位
int binVal3 = 0B10000000000000000000000000000011;
System.out.println(binVal1);//输出212
System.out.println(binVal2);//输出105
System.out.println(binVal3);//输出-2147483645
当定义32位二进制整数时,最高位其实是符号位,当符号位是1时,表示他是一个负数,负数在计算机里是以补码的形式存在的,因此还需要换算成原码。
所有数字在计算机底层都是以二进制形式存在的,原码是直接将一个数值换算成二进制数,但计算机以补码的形式保存所有的整数。补码的计算规则:正数的补码和原码完全不变,负数的补码是其反码加1,;反码是对原码按位取反,只是最高位(符号位)保持不变。
将上述的二进制整数binVal3转换成十进制的过程如下
补码:10000000000000000000000000000011
↓ 补码-1得到反码
反码:10000000000000000000000000000010
↓ 符号位不变,其他位取反
原码:11111111111111111111111111111110
正如前面所指出的,整数值默认就是int类型,因此使用二进制形式定义整数时,二进制整数默认占32位,其中第32位是符号位;如果在二进制整数后添加l或L后缀,那么这个二进制整数默认占64位,其中第64位是符号位。例如如下程序。
/*
定义一个8位的二进制整数,该数值默认占32位,因此它是一个正数
只是强制类型转换成byte时产生了溢出,最终导致binVal4变成了-23
*/
byte binVal4 = (byte) 0b11101001;
/*
定义一个32位的二进制整数,最高位是1,
但由于数值后添加了L后缀,因此该整数实际占64位,第32位的1不是符号位
*/
long binVal5 = 0b10000000000000000000000000000011L;
System.out.println(binVal4); //输出-23
System.out.println(binVal5); //输出2147483651
上面程序中粗体字代码与前面程序片段的粗体字代码基本相同,只是定义二进制整数时添加了"L"后缀,这就表明把他当成long类型处理,因此该整数实际占64位。此时的第32位不再是符号位,因此它依然是一个正数。
至于程序中的byte binVal4 = (byte)0b11101001;代码,其中0b11101001依然是一个32位的正整数,只是程序进行强制类型转换时发生了溢出,导致它变成了负数。关于强制类型转换的知识请参考本章3.5节。
字符型
字符型通常用于表示单个的字符,字符型值必须使用单引号(')括起来。Java语言使用16位的Unicode字符集作为编码方式,而Unicode被设计成支持世界上所有书面语言的字符,包括中文字符,因此Java程序支持各种语言的字符。
字符数值有如下三种表示形式。
直接通过单个字符来指定字符型值,例如'A'、'9'、'0'等。
通过转义字符表示特殊字符转型,例如'\n','\t'等。
直接使用Unicode值来表示字符型值,格式是'\uXXXX',其中XXXX代表一个十六进制的整数。Java语言中常用的转移字符如下所示。
| 转义字符 | 说明 | Unicode表示方式 |
|---|---|---|
| \b | 退格符 | \u0008 |
| \n | 换行符 | \u000a |
| \r | 回车符 | \u000d |
| \t | 制表符 | \u0009 |
| " | 双引号 | \u0022 |
| ' | 单引号 | \u0027 |
| \ | 反斜线 | \u005c |
字符型值也可以采用十六进制编码方式来表示,范围说'\u0000'~'\uFFFF' ,一共可以表示65536个字符,其中前256个('\u0000'~'\u00FF')字符和ASCII码中的字符完全重合
由于计算机底层保存字符时,实际是保存该字符对应的编号,因此char类型的值也可以直接作为整型值来使用,它相当于一个16位的无符号整数,表数范围是0~65535。
char类型的变量、值完全可以参与加减乘除等数学运算,也可以比较大小——实际上都是用该字符对应的编码参与运算。
如果把0~65535范围内的一个int整数赋给char类型变量,系统会自动把这个int整数当成char类型来处理。
下面程序简单示范了字符型变量的用法。
public class test1 {
static public void main(String[] args) {
//直接指定单个字符作为字符值
char aChar = 'a';
System.out.println(aChar);
//使用转义字符来作为字符值
char enterChar = '\r';
System.out.println(enterChar);
//使用Unicode编码值来指定字符串
char ch = '\u9999';
System.out.println(ch);
//将输出一个'香'字符值
char zhong = '疯';
System.out.println(zhong);
//直接将一个char变量当成int类型变量使用
int zhongValue = zhong;
System.out.println(zhongValue);
//直接把一个0~65535范围内的int整数赋给一个char变量
char c = 97;
System.out.println(c);
}
}
Java没有提供表示字符串的基本数据类型,而是通过String类来表示字符串,由于字符串由很多字符组成,因此字符串要使用双引号括起来。如下代码:
//下面代码定义了一个a变量,它是一个字符串实例的引用,它是一个引用类型的变量
String a = "沧海月明珠有泪,蓝田日暖玉生烟。";
在java中,引用类型可以分为两大类:值类型,引用类型。
其中值类型就是基本数据类型,如int,double类型,而引用类型就是除了基本数据类型之外的所有类型(如class类型),所有的类型在内存中都会分匹配
浮点型
java的浮点类型有两种:float和double。Java的浮点类型有固定的表数范围和字段长度,字段长度和表数范围与机器无关。Java的浮点数遵循IEEE754标准,采用二进制数据的科学计数法来表示浮点数,对于float型数值,第1位是符号位,接下来8位表示指数,在接下来的23位来表示尾数;对于double类型数值,第1位也是符号位,接下来的11位表示指数,在接下来的52位表示尾数。
double类型表示双精度浮点数,float类型代表单精度浮点数,一个double类型的数值占8字节,64位,一个float类型的数值占4字节,32位。
Java的浮点类型默认是double类型,如果希望Java把一个浮点类型值当成float类型处理,应该在这个浮点类型值后面紧跟f或者F。当然也可以在一个浮点数后添加一个d或者D后缀,强制指定是double类型,但通常没必要。
Java还提供了三个特殊的浮点数值:正无穷大、负无穷大和非数,用于表示溢出和出错,例如,使用一个正数除以0将得到正无穷大,使用一个负数除以0将得到负无穷大,0.0除以0.0将对一个负数开方得到一个非数。正无穷大通过Double或Float类的POSITIVE_INFINITY表示:负无穷大通过Double或Float类的NEGATIVE_INFINITY表示,非数通过Double或Float类的NaN表示。
必须指出的是,所有正无穷大数值都是相等的,所有的负无穷大数值都是相等的;而NaN不与任何数值相等,甚至和NaN都不相等。
下面程序示范了上面介绍的关于浮点数的各个知识点。
public class test1 {
static public void main(String[] args) {
float af = 5.2345556f;
//下面将看到af的值已经发生了改变
System.out.println(af);
double a = 0.0;
double c = Double.NEGATIVE_INFINITY;
float d = Float.NEGATIVE_INFINITY;
System.out.println(c==d);
//0.0除以0.0将出现非数
System.out.println(a / a);
//两个非数之间是不相等的
System.out.println(a/a == Float.NaN);
//所有正无穷大都是相等的
System.out.println(6.0/0 == 555.0/0);
//下面代码将抛出除以0的异常
System.out.println(0/0);
}
}
布尔型
boolean只有true和false
字符串"true"和"false"不会直接转换成boolean类型,但如果使用一个boolean类型的值和字符串进行连接运算,则boolean类型的值将会自动转换为字符串,看下面代码
public class test1 {
static public void main(String[] args) {
String str = true + "";
System.out.println(str); // true
}
}
使用var定义变量
Java10开始使用了var定义局部变量;var相等于一个动态类型,使用var定义的局部变量的类型由编译器自动推断——定义变量时分配了什么类型的初始值,那该变量就是什么类型。
需要说明的是,Java的var与Javascript的var截然不同,JavaScript本质上是弱类型语言,因此JavaScript使用var定义的变量并没有明确的类型;但Java是强类型语言,因此Java使用var定义的变量依然有明确的类型——为局部变量指定初始值时,该变量的类型就确定下来了。
因此,使用var定义局部变量的时候们必须定义局部变量的同时指定初始值,否则编译器无法推断该变量的类型。
例如,如下代码使用var定义了多个局部变量。
public class test1 {
static public void main(String[] args) {
var a = 20; //被赋值为20,因此a的类型是int
System.out.println(a);
//a=1.6 //这行代码会报错,不兼容的类型
var b = 3.4;
System.out.println(b);
var c = (byte)13;
System.out.println(c);
//c = a; //这行代码会报错,不兼容的类型
//var d; 这行代码会报错,无法推断局部变量d的类型
}
}
使用var定义的变量不仅可以是基本类型,也可以是字符串等引用类型,例如如下代码;
var st = "Hello"; //被赋值位"Hello",因此st的类型是String
st = 5; //这行代码会报错,不兼容的类型
从上面介绍可以看出,Java引入var属于"向潮流投降"——由于Java本质上是强类型语言,因此使用var定义局部变量只是形式的改变,这些变量依然有明确的类型。
使用var是双刃剑,优点:代码更简洁,不管是什么类型的局部变量,直接使用var声明即可;其缺点在于:变量类型的可读性降低了。
基本类型的类型转换
自动类型转换
自动类型转换图
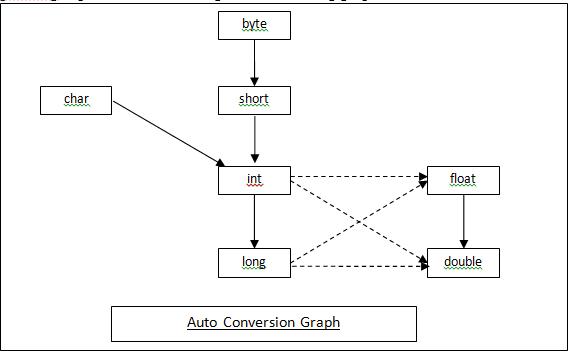
上面的数值类型可以自动类型转换为下面的数值类型,下面程序示范了自动类型转换。
public class test1 {
static public void main(String[] args) {
int a = 6;
//int类型可以自动转换为float类型
float f = a;
//下面将输出6.0
System.out.println(f);
//定义一个byte类型的整数变量
byte b = 9;
//下面代码将出错,byte类型不能自动转换为char类型
//char c = b;
//byte类型变量可以自动类型转换为double类型
double d = b;
//下面将输出9.0
System.out.println(d);
}
}
不仅如此,当把任何基本类型的值和字符串值进行连接运算时,基本类型的值将自动类型转换为字符串类型。
public class test1 {
static public void main(String[] args) {
//一个基本类型的值和字符串进行连接运算时,基本类型的值将自动转换为字符串
String str2 = 3.5f + "";
//下面将输出3.5
System.out.println(str2);
//下面语句输出 7Hello!
System.out.println(3+4+"Hello!");
//下面语句会输出Hello!34,因为Hello! + 3 会把3当成字符串处理
//而后再把4当成字符串处理
System.out.println("Hello!"+3+4);
}
}
强制类型转换
当进行强制类型转换时,类似于把一个大瓶子里的水倒入一个小瓶子,如果大瓶子里的水不多还好,但如果大瓶子里的水很多,将会引起溢出,从而造成数据丢失。这种转换也被称为"缩小转换(Narrow Conversion)"
public class test1 {
static public void main(String[] args) {
var iValue = 233;
//强制把一个int类型的值转换为byte类型的值
byte bValue = (byte)iValue;
//将输出-23
System.out.println(bValue);
var dValue = 3.98;
//强制把一个double类型的值转换为int类型的值
int tol = (int)dValue;
//将输出3
System.out.println(tol);
}
}
下面程序示范了如何生成一个6位的随机字符串
public class test1 {
static public void main(String[] args) {
var result = "";
//进行了6次循环
for (var i = 0 ; i < 6; i++){
//生成一个97~122之间的int类型整数
var intVal = (int)(Math.random()*26 + 97);
result += (char)intVal;
}
System.out.println(result);
}
}
Java为8种基本类型都提供了对应的包装类:boolean对应Boolean、byte对应Byte、short对应Short、int对应Integer、long对应Long、char对应Character、float对应Float、double对应Double,8个包装类都提供了一个parseXxx(String str)静态方法用来将字符串转换为基本类型。
表达式类型的自动提升
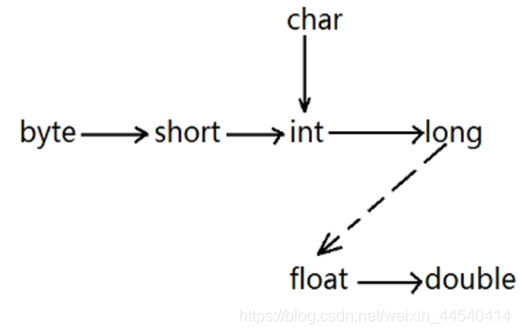
当一个算术表达式包含多个基本类型的值时,整个算术表达式的数据类型将发生自动提升,所有的byte、short和char类型将被提升到int类型
排列如上图所示,位于箭头右边类型的等级高于位于箭头左边类型的等级
public class test1 {
static public void main(String[] args) {
short sValue = 2;
//下面将一个int类型值赋给short类型变量的时候将发生错误
sValue = sValue - 2;
}
}
上面的"sValue-2"表达式的类型将被提升到int类型,这样将右边的int类型赋值给左边的short类型变量,从而引起错误。
下面代码是表达式类型自动提升的正确示例代码
public class test1 {
static public void main(String[] args) {
byte b = 40;
var c = 'a';
var i = 23;
var d = .314;
//右边表达式中最高等级操作数为d(double类型)
//则右边表达式的类型为double类型,故赋值给一个double类型变量
double result = b + c + i * d;
//将输出144.222
System.out.println(result);
}
}
public class test1 {
static public void main(String[] args) {
var val = 3;
//右边表达式中两个操作数都是int类型,故右边表达式的类型是int
int intResult = 23 / val ;
System.out.println(intResult); //输出7
}
}
//输出字符串 Hello!a7
System.out.println("Hello!"+'a'+7);
//输出字符串104Hello!
System.out.println('a'+7+"Hello!");
直接量
常量池指的是在编译器被确定,并被保存在已编译的.class文件中的一些数据。它包括关于类、方法、接口中的常量,也包括字符串直接量。
Java会确保每个字符串常量只有一个,不会产生多个副本。例子中的s0和s1中的"hell0"都是字符串常量,他们在编译的时候就被确定了,所以s1 == s2 返回true
public class test1 {
static public void main(String[] args) {
String s1 = "Hello";
String s2 = "Hello";
System.out.println(s1 == s2); //true
}
}
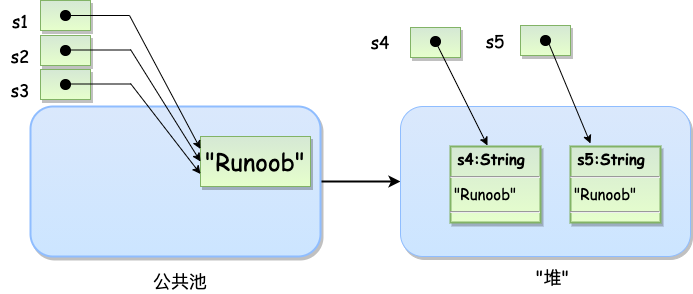
String创建的字符串存储在公共池中,而new创建的字符串对象在堆上
String s1 = "Runoob"; // String 直接创建
String s2 = "Runoob"; // String 直接创建
String s3 = s1; // 相同引用
String s4 = new String("Runoob"); // String 对象创建
String s5 = new String("Runoob"); // String 对象创建
运算符
算数运算符
加减乘除和求余等基本算术运算符
/:除法运算符。
如果两个操作数都是整数类型,则除数不可以是0,否则将引发除以0异常。
但如果两个操作数有一个是浮点数,或者两个都是浮点数,则计算结果也是浮点数,这个结果就是自然除法的结果。而且此时允许被除数是0,或者0.0,得到结果就是正无穷大或负无穷大。
public class test1 {
static public void main(String[] args) {
var a = 5.2;
var b = 3.1;
var div = a / b;
//div的值将是1.6774193548387097
System.out.println(div);
//输出正无穷大 Infinity
System.out.println("5除以0.0的结果是:" + 5 / 0.0);
//输出负无穷大 -Infinity
System.out.println("-5除以0.0的结果是:" + -5 / 0.0);
//下面代码将出现异常
// java.lang.ArithmeticException: / by zero
System.out.println("-5除以0的结果是:"+ -5/0);
}
}
%:求余运算符。由于求余操作也要进行除法运算,因此如果求余运算的两个操作数都是整数类型,则求余运算的第二个操作数不能是0,否则将引发除以零异常。如果求余运算的两个操作数有一个或者两个都是浮点型,则允许第二个操作数是0或0.0,只是求余运算的结果是非数:NaN。0对0.0对零以外的任何数求余都将得到0或0.0。看如下程序
public class test1 {
static public void main(String[] args) {
var a = 5.2;
var b = 3.1;
var mod = a % b;
System.out.println(mod); //2.1
System.out.println("5对0.0求余的结果是:" + 5 % 0.0);//输出非数:NaN
System.out.println("-5.0对0.0求余的结果是:" + -5.0 % 0.0);//输出非数:NaN
System.out.println("0对5.0求余的结果是:" + 0 % 5.0);//输出0.0
System.out.println("0对0.0求余的结果是:" + 0 % 0.0);//输出非数NaN
//下面代码将出现异常:java.lang.ArithmeticException; /by Zero
System.out.println("-5对0求余的结果是:" + -5 % 0);
}
}
Java并没有提供其他更复杂的运算符,如果需要完成乘方、开方等运算,则可借助于java.lang.Math类的工具方法完成复杂的数学运算,见如下代码。
public class test1 {
static public void main(String[] args) {
var a = 3.2; //定义变量a为3.2
//求a的5次方,并将计算结果赋给b
double b = Math.pow(a,5);
System.out.println(b);//输出b的值
double c = Math.sqrt(a);
System.out.println(b);//输出c的值
//计算随机数,返回一个0~1之间的伪随机数
double d = Math.random();
System.out.println(d);//输出随机数d的值
//求1.57的sin函数值:1.57被当成弧度值
double e = Math.sin(1.57); //角度接近π/2
System.out.println(e);//输出接近1
}
}
拓展运算符:
-=
*=
/=
%=
&=
|=
^=
<<=
>>=
>>>=
只要能使用这种拓展后的赋值运算符,通常都建议使用它们,因为这种运算符不仅具有更好的性能,而且程序会更加健壮。
public class test1 {
static public void main(String[] args) {
byte a = 5;
//下面语句出错,因为5默认是int类型,a+5就是int类型
//把int类型赋值给byte类型的变量,所以出错
//a = a + 3;
//下面语句就不会出错,因为拓展后的赋值运算符有更好的性能,程序会更加健壮
a += 3;
}
}
逻辑运算符
&&:与,前后两个操作数必须都是true才返回true,否则返回false
&:不断路与,作用与&&相同,但不会短路
||:或,只要两个操作数中有一个是true,就可以返回true,否则返回false
|:不短路或,作用与||相同,但不会短路
!:非,只需要一个操作数,如果操作数为true,则返回false;如果操作数是false,则返回true
^:异或,当两个操作数不同时才返回true,如果两个操作数相同则返回false。
下面代码示范了或、与、非、异或四个逻辑运算符的执行示意
public class test1 {
static public void main(String[] args) {
//直接对false求非运算,得到true
System.out.println(!false);
//5>3返回true,'6'转换为整数54,‘6’>10返回true,求与后返回true
System.out.println(5 > 3 && '6' > 10);
//4>=5返回false,'c'>'a'返回true。求或后返回true
System.out.println(4 >= 5 || 'c' > 'a');
//4>5 返回false,'c'>'a‘返回true,两个不同的操作数求异或返回true
System.out.println(4 >= 5 ^ 'c' > 'a');
}
}
对于|与||的区别参见如下代码
public class test1 {
static public void main(String[] args) {
var a = 5;
var b = 10;
// 对 a > 4 和 b++ > 10来或运算
if (a > 4 | b++ > 10){
//输出a的值是5,b的值是11
System.out.println("a="+a+","+"b="+b);
}
}
}
public class test1 {
static public void main(String[] args) {
var a = 5;
var b = 10;
// 对 a > 4 和 b++ > 10来或运算
if (a > 4 || b++ > 10){
//输出a的值是5,b的值是10
System.out.println("a="+a+","+"b="+b);
}
}
}
&和&&的区别与此类似:&总会计算前后两个操作数,而&&先计算左边的操作数,如果左边的操作数为false,则直接返回false,根本不会计算右边的操作数。
流程控制与数组
Java11改进的Switch分支语句
swicth语句后面的控制表达式的数据类型只能是byte、short、char、int四种整数类型,枚举类型和java.lang.String类型(从Java7才允许),不能是boolean类型。
switch(expression)
{
case condition1:
{
statement(s)
break;
}
case condtion2:
{
statement(s)
break;
}
……
case conditionN:
{
statement(s)
break;
}
default:
{
statement(s)
}
}
这种分支语句的执行是先对expression求值,然后依次匹配condition1、condition2、……、conditionN等值,遇到匹配的值即执行对应的执行体;如果所有case标签后的值都不与expression表达式的值相等,则执行default标签后的代码块。
swicth语句中的defaulti标签看似没有条件,其实是有条件的,条件就是expression表达式的值不能与前面任何一个case标签后的值相等。
public class test1 {
static public void main(String[] args) {
var score = 'C';
switch (score){
case 'F':
System.out.println("优秀");
break;
case 'B':
System.out.println("还行");
break;
case 'C':
System.out.println("傻逼");
//break;
case 'D':
System.out.println("废物");
//break;
case 'E':
System.out.println("屎B");
//break;
default:
System.out.println("草泥马");
}
}
}
swicth语句允许case没有break;语句,但是这种做法可能引入一个陷阱。例如上面的程序,将会看到以下运行结果
傻逼
废物
屎B
草泥马
Java11编译器做了一些改进,如果开发者忘记了case块后面的break语句,Java11编译器会生成警告:“[fallthrough]可能无法实现case”。这个警告在以前需要为javac指定-X:fallthrough选项才能显示出来。
**从Java7开始增强了switch语句的功能,允许swtich语句的控制表达式是java.lang.String类型的变量或表达式——只能是java.lang.String类型,不能是StringBuffer或StringBuilder这两种字符串类型。
数组类型
Java数组既可以存储基本类型的数据,也可以存储引用类型的数据,只要所有的数组元素具有相同的类型即可。
值得指出的是,数组也是一种数据类型,它本身是一种引用类型。利用int是一个基本类型,但int[] (这是定义数组的一种方式数组的一种方式)就是一种引用类型了。
定义数组
Java语言支持两种语法格式来定义数组
type[] arrayName;
type arrayName[];
建议使用第一种方式,type[]是一种新类型,具有更好的语意,而且具有更好的可读性。
Java的模仿者C#就不再支持type arrayName[]这种语法,它只支持第一种定义数组的语法,越来越多的语言不再支持type arrayName[]这种数组定义语法。
数组是一种引用类型的变量,使用它定义一个变量时,仅仅是定义了一个引用变量(也就是定义了一个指针),这个引用变量还未指向任何有效的内存,因此定义数组的时候不能指定数组的长度。
因为定义数组只是定义了一个引用变量,并未指向任何有效的内存空间,所以还没有内存空间来存储数组元素,因此这个数组也不能使用,只有对数组进行初始化后才可以使用。
数组的初始化
Java语言中数组必须先初始化才可以使用。所谓初始化,就是为数组的数组元素分配内粗空间,并为每个数组元素赋初始值。
数组的初始化有两种方式:
静态初始化:初始化时由程序员显示指定每个数组元素的初始值,由系统决定数组长度。
动态初始化:初始化时程序员只指定数组长度,由系统为数组元素分配初始值。
动态初始化只指定数组的长度,由系统为每个数组元素指定初始值。动态初始化语法格式如下:
arrayName = new type [length];
静态和动态初始化一样,type必须与定义数组时所使用的type类型相同,或者是定义数组时使用的type类型的子类。下面代码示范了如何进行动态初始化
int[] prices = new int[5];
Object[] books = new String[4];
执行动态初始化的时候,程序员只需指定数组的长度,即为每个数组元素指定所需的内存空间,系统将负责为这些数组元素分配初始值。指定初始值时,系统按如下规则分配初始值。
数组元素的类型是基本类型中的整数类型(byte、short、int 和 long)则数组元素的值是0。
数组元素的类型是基本类型中的浮点类型(float、double),则数组元素的值是0.0。
数组元素的类型是基本类型中的字符类型(char),则数组元素的值是'\u0000'。
数组元素的类型是基本类型中的布尔类型(boolean),则数组元素的值是false。
数组元素的类型是引用类型(类、接口和数组),则数组元素的值是null。
不要同时使用静态初始化和动态初始化,也就是说,不要在进行数组初始化时,既指定数组的长度,也为每个数组元素分配初始值
深入数组
内存中的数组
public class test1 {
static public void main(String[] args) {
int[] a = {5,7,20};
var b = new int[4];
System.out.println("b数组的长度为:"+b.length);
//循环输出a数组的元素
for (int i=0,len =a.length;i<len;i++){
System.out.println(a[i]);
}
//循环输出b数组的元素
for (int i =0,len = b.length;i<len;i++){
System.out.println(b[i]);
}
//因为a是int[]类型,b也是int[]类型,所以可以将a的值赋值给b
b = a;
//再次输出b数组的长度
System.out.println("b数组的长度为:"+b.length);
}
}
上面看起来似乎数组的长度是可变的,但这只是一个假象。必须牢记:定义并初始化一个数组后,在内存中分配了两个空间,一个用于存放数组的引用变量,另一个用于存放数组本身。
当程序定义并初始化了a、b两个数组后,系统内存中实际上产生了4块内存区,其中栈内存中有两个引用变量:a和b;堆内存中也有两块内存区,分别用于存储a和b引用所指向的数组本身。
当执行b=a的时候,系统会把a的值赋给b,a和b都是引用类型变量,存储的是地址。因此把a的值赋给b后,就是让b指向a所指向的地址。
因此,堆内存中的第一个数组具有了两个引用:a变量和b变量都引用了第一个数组。此时第二个数组就失去了引用,变成垃圾,只有等待垃圾回收器来回收它——但它的长度依然不会改变,直到它彻底消失。
程序员看待一个数组时,一定要把数组堪称两个部分,一部分是数组引用,也就是代码中定义的数组引用变量;还有一部分是实际的数组对象,这部分是在堆内存中运行的,通常无法直接访问它,只能通过数组引用变量来访问
基本类型数组的初始化
public class test1 {
static public void main(String[] args) {
int[] iArr;
iArr = new int[5];
for (var i=0;i<iArr.length;i++){
iArr[i]=i+10;
}
}
}
执行了int[] iArr;代码后,仅在栈内存中定义了一个空引用(就是iArr数组变量),这个引用并未指向任何有效的内存,当然无法指定数组的长度。
当执行iArr = new int[5];动态初始化后,系统将负责为该数组分配内存空间,并分配默认的初始值,所有数组元素都被赋为值0。
此时iArr数组的每个数组元素的值都是0,当循环为该数组的每个数组元素依次赋值后,此时每个数组元素的值都变成程序显示指定的值。
没有对象数组
Java语言里的数组类型是引用类型,因此数组变量其实是一个引用,这个引用指向真实的数组内存。数组元素的类型也可以是引用,如果数组元素的引用再次指向真实的数组内存,这种情形看上去很像多维数组。
public class test1 {
static public void main(String[] args) {
int[][] a;
a = new int[4][];
for (int i = 0 , len = a.length ; i < len ; i++){
System.out.println(a [i]);
}
//初始化a数组的第一个元素
a[0] = new int[2];
a[0][1] = 6;
for (int i = 0 , len = a[0].length ;i <len ;i++){
System.out.println(a[0][i]);
}
}
}
上面程序中把a这个二维数组当成一维数组来处理,只是每个数组元素都是null
第一行int[] [] a;将在栈内存中定义一个引用变量,这个变量并未指向任何有效的内存空间,此时的堆内存中还未为这行代码分配任何存储区
程序对a数组执行初始化:a = new int[4] [];,这行代码让a变量指向一块长度为4的数组内存,这个长度为4的数组里每个数组元素都是引用类型(数组类型),系统为这些数组元素分配默认的初始值:null。
因为程序采用动态初始化a[0]数组,因此系统将为a[0]所引用数组的每个元素分配默认的初始值:0,然后程序显示为a[0]数组的第二个元素赋值为6
不能让a[0] [2]再次指向一个数组,形成三维数组,因为当定义a数组的时候,已经确定了a数组的数值类型是int类型,所以a[0] [2]只能存储int类型的变量。 对于其他弱类型语言,例如JavaScript和Ruby等,确实可以把一维数组无限扩展,扩展成二维数组、三维数组……如果想在Java语言中实现这种可无限扩展的数组,则可以定义一个Object类型的数组,这个数组的元素是Object类型,因此可以再次指向一个Object[]类型的数组,这样就可以从一维数组扩展到二维数组、三维数组……
还可以使用静态初始化的方式来初始化二维数组。使用静态初始化方式来初始化二维数组时,二维数组的每个数组元素都是一维数组,因此必须指定多个一维数组作为二维数组的初始化值。如下代码所示
public class test1 {
static public void main(String[] args) {
//使用静态初始化语法来初始化一个二维数组
String[][] str1 = new String[][]{new String[3], new String[]{"hello"}};
//使用简化的静态初始化语法来初始化二维数组
String[][] str2 = {new String[3], new String[]{"hello"}};
}
}
操作数组的工具类:Arrays
Java提供的Arrays类里包含的一些static修饰的方法可以直接操作数组,这个Arrays类里已经包含了如下几个static修饰的方法(static修饰的方法可以直接通过类名调用)。
- int binarySearch(type[] a,type key):使用二分法查询key元素值在a数组中出现的索引;如果a数组不包含key元素值,则返回负数。调用该方法时要求数组中元素已经按升序排列,这样才能得到正确结果。
- int binarySearch(type[] a,int fromIndex,int toIndex,typekey):这个方法与前一个方法类似,但它只搜索a数组中fromIndex到toIndex索引的元素。调用该方法时要求数组中元素已经按升序排列,这样才能得到正确结果。
- type[] copyOf(type[] original,int length):这个方法将会把original数组复制成一个新数组,其中length是新数组的长度。如果length大于original数组的长度,则新数组的前面元素就是原数组的所有元素,后面补充0(数值类型)、false(布尔类型)或者null(引用类型)。
- type[]copyOfRange(type[] original,int from, int to):这个方法与前面方法相似,但这个方法只复制original数组的from索引到to索引的元素。
- boolean equals(type[] a,type[] a2):如果a数组和a2数组的长度相等,而且a数组和a2数组的数组元素也一一相同,该方法将返回true
- void fill(type[] a,type val):该方法将会把a数组的所有元素赋值为val。
- void finll(type[]a, int fromIndex, int toIndex, type val):该方法与前一个方法的作用相同,区别只是该方法仅仅将a数组的fromIndex到toIndex索引的数组元素赋值为val。
- void sort(type[] a):该方法对a数组的数组元素进行排序。
- void sort(type[] a, int fromIndex, int toIndex):该方法与前一个方法相似,区别是该方法仅仅对fromIndex到toIndex索引的元素进行排序
- String toString(type[] a):该方法将一个数组转换成一个字符串。该方法按顺序把多个数组元素连缀到一起,多个数组元素使用英文逗号(,)和空格隔开
除此之外,在System类里也包含了一个static void arraycopy (Object src, int srcPos, Object dest, int destPos, int length)方法,该方法可以将src数组里的元素赋值给dest数组的元素,其中srcPos指定从src数组的第几个元素开始赋值,length参数指定将src数组的多少个元素值赋给dest数组的元素。
Java8增强了Arrays类的功能,为Arrays类增加了一些工具方法,这些工具可以充分利用多CPU并行的能力来提高设值、排序的性能。下面是Java8为Arrays类增加的工具方法
- void parallelPrefix(xxx[] arrays, XxxBinaryOperator op):该方法使用op参数指定的计算公式计算得到的结果作为新的数组元素。op计算公式包括left、right两个形参,其中left代表新数组中前一个索引处的元素,right代表array数组中当前索引处的元素。新数组的第一个元素无需计算,直接等于array数组的第一个元素。
- void parallelPrefix(xxx[]arrays, int fromIndex, int toIndex, XxxBinaryOperator op):该方法与上一个方法相似,区别是该方法仅重新计算fromIndex到toIndex索引的元素
- void setAll(xxx[] array, IntToXxxFunction gengerator):该方法使用指定的生成器(generator)为所有数组元素设置值,该生成器控制数组元素的值的生成算法。
- void parallelSetAll(xxx[] array, IntToXxxFunction generator):该方法的功能与上一个方法相同,只是该方法增加了并行能力,可以利用多CPU并行来提高性能
- void parallelSort(xxx[] a):该方法的功能与Arrays类以前就有的sort()方法相似,只是该方法增加了并行能力,可以利用多CPU并行来提高性能
- void parallelSort(xxx[] a, int fromIndex, int toIndex):该方法与上一个方法相似,区别是该方法仅对fromIndex到toIndex索引的元素进行排序。
- Spliterator.OfXxx spliterator(xxx[] array):将该数组所有元素转换成对应的Spliterator对象。
- Spliterator.OfXxx spliterator(xxx[] array, int startInclusive, int endExclusive):该方法与上一个方法相似,区别是该方法仅转换startInclusive到endInclusive索引的元素
- XxxStream stream(xxx[] array):该方法将数组转换为Stream,Stream是Java8新增的流式变成的API。
- XxxStream steam(xxx[] array, int startInclusive, int endInclusive):该方法与上一个方法相似,区别是该方法仅将fromIndex到toIndex索引的元素转换为Stream。
数组应用举例
Math.round(double num)
参数加0.5,然后进行下取整
下面是将浮点数分成整数部分和小数部分、把一个4位数字字符串转换成一个中文读法
import java.util.Arrays;
public class Change {
private String[] hanArr = {"零", "壹", "贰", "叁", "肆", "伍", "陆", "柒", "捌", "玖"};
private String[] unitArr = {"十", "百", "千"};
private String[] divide(double num) {
var zheng = (int) num;
var xiao = Math.round((num - zheng) * 100);
return new String[]{zheng + "", String.valueOf(xiao)};
}
private String toHanStr(String numStr) {
var result = "";
int numLen = numStr.length();
String DelayAdd = null;
for (var i = 0; i < numLen; i++) {
var num = numStr.charAt(i) - 48;
if (num != 0) {
if (DelayAdd != null) {
result += DelayAdd;
DelayAdd = null;
}
result += hanArr[num] + (i > numLen - 2 ? "" : unitArr[numLen - 2 - i]);
} else {
DelayAdd = hanArr[0];
}
}
return result;
}
public static void main(String[] args) {
Change change = new Change();
System.out.println(Arrays.toString(change.divide(101.2222)));
System.out.println(change.toHanStr("6031"));
}
}
五子棋
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class chess {
private static int BOARD_SIZE = 15;
private String[][] board;
public void initBoard(){
board = new String[BOARD_SIZE][BOARD_SIZE];
for (var i = 0 ; i < BOARD_SIZE ; i++){
for (var j = 0 ; j < BOARD_SIZE ; j++){
board[i][j] = "十";
}
}
}
public void printBoard(){
for (var i = 0 ; i < BOARD_SIZE ; i++){
for (var j = 0 ; j < BOARD_SIZE ; j++){
System.out.print(board[i][j]);
}
System.out.print("\n");
}
}
public static void main(String[] args) throws Exception {
var chess = new chess();
chess.initBoard();
chess.printBoard();
var br = new BufferedReader(new InputStreamReader(System.in));
String inputStr = null;
while((inputStr = br.readLine()) != null){
String [] posStrArr = inputStr.split(",");
var xPos= Integer.parseInt(posStrArr[0]);
var yPos = Integer.parseInt(posStrArr[1]);
chess.board[yPos - 1][xPos-1] = "●";
chess.printBoard();
System.out.println("请输入您下棋的坐标,应以x,y的格式:");
}
}
}
面向对象
面向对象(上)
学了4天,算是把面向对象大致学完了,大多数都是理解性的内容,不太好做笔记,但是感觉学得有点迷迷糊糊的,还是决定重新过一遍,再把笔记做上,这里只写自己记忆不深刻的知识点
定义类
对于一个类来说,可以包含三种最常见的成员:构造器、成员变量和方法,三种成员都可以定义零个或者多个,如果三种成员都之定义零个,就是定义了一个空类,这没有太大的实际意义。
Java里定义类的简单语法如下:
[修饰符] class 类名{
零个到多个构造器定义……
零个到多个成员变量……
零个到多个方法……
}
定义成员变量的语法格式如下:
[修饰符] 类型 成员变量名 [= 默认值];
修饰符可以省略,修饰符有public、protected、private、static、final,其中public、protected、private三个最多只能出现其中一个,可以与static、final组合起来修饰成员变量
类型可以是任何数据类型,包括基本类型和引用类型
定义方法的语法格式如下:
[修饰符] 方法返回值类型 方法名(形参列表){
//由零条到多条可执行语句组成的方法体
}
修饰符可以省略,修饰符有public、protected、private、static、final、abstract,其中public、protected、private三个最多只能出现其中一;abstract和final最多只能出现其中之一,它们可以与static组合起来修饰方法。
定义构造器的语法与定义方法的语法格式很像,定义构造器的语法格式如下:
[修饰符] 构造器名(形参列表){
//由零条到多条可执行语句组成的构造器执行体
}
修饰符可以省略,修饰符有public、protected、private其中之一。
构造器名必须和类名相同。
对象、引用和指针
Person p = new Person();
var p2 = p; ②
如上代码,p引用变量本身只存储了一个地址值,并未包含任何实际数据,但它指向实际的Person对象,当访问p引用变量和方法时,实际上是访问p所引用对象的成员变量和方法。
不管是数组还是对象,当程序访问引用变量的成员变量或方法时,实际上是访问该引用变量所引用的数组、对象的成员变量或方法。
引用变量是在栈里的,而实际的变量本身在堆里
②:堆内存里的对象可以有多个引用,即多个引用变量指向同一个对象
如果希望垃圾回收器回收某个对象,只需切断该对象的所有引用变量和它之间的关系即可,也就是把这些引用变量赋值为null。
对象的this引用
this关键字总是指向调用该方法的对象
对于static修饰的方法而言,则可以使用类直接调用该方法,如果在static修饰的方法中使用this关键字,则这个关键字就无法指向合适的对象。所以,static修饰的方法中不能使用this引用。由于static修饰的方法不能使用this引用,所以static修饰的方法不能访问不使用static修饰的普通成员,因此Java语法规定:静态成员不能直接访问非静态成员。
static修饰的方法属于类,而不属于对象,因此调用static修饰的方法的主调总是类本身,如果允许在static修饰的方法中出现this引用,那将导致this无法引用有效的对象,导致程序编译错误
Java有一个让人极易"混淆"的语法,它允许适用对象来调用static修饰的成员变量、方法,但实际上这是不应该的。前面已经介绍过,static修饰的成员属于类本身,而不属于该类的实例,既然static修饰的成员完全不属于该类的实例,那么就不应该允许实例去调用static修饰的成员变量和方法!所以请读者牢记一点:Java编程时不要使用对象去调用static修饰的成员变量、方法,而是应该使用类去调用static修饰的成员变量、方法!如果在其他Java代码中看到对象调用static修饰的成员变量、方法的情形,则可以把这种当成假象,将其替换成用类来调用static修饰的成员变量、方法的代码。
方法详解
方法的参数传递机制
Java里方法的参数传递方式只有一种:值传递。所谓值传递,就是将实际参数值的副本(复制品)传入方法内,而参数本身不会受到任何影响。
public class PrimitiveTransferTest{
public static void swap(int a, int b){
var tmp = a;
a = b;
b = tmp;
System.out.println("swap方法里,a的值是" + a + ";b的值是" + b);
}
public static void main(String[] args){
var a = 6;
var b = 9;
swap(a,b);
System.out.println("交换结束后,a=" + a + "b=" + b);
}
}
系统执行swap()方法时,并将main()方法中的a、b变量作为参数值传入swap()方法,传入swap()方法的只是a、b的副本,而不是a、b本身。
在main()方法中调用swap()方法时,main()方法还未结束,因此,系统分别为main()方法和swap()方法分配两块栈区,用于保存main()方法和swap()方法的局部变量。main()方法中的a、b变量作为参数值传入swap()方法,实际上是在swap()方法栈区中重新产生了两个变量a、b,并将main()方法栈区中a、b变量的值分别赋给swap()方法栈区中的a、b参数(就是对swap()方法的a、b形参进行了初始化)。此时,系统存在两个a变量,两个b变量,只是存在于不同的方法栈区中而已。
程序改变的只是swap()方法栈区中的a、b。这就是值传递的本质:当系统执行方法时,系统为形参执行初始化,就是把实参变量的值赋给方法的形参变量,方法里操作的并不是实际的实参变量。
前面看到的是基本类型的参数传递,Java对于引用类型的参数传递,一样采用的是值传递方式。只是容易引起初学者的误会。
class DataWrap{
int a;
int b;
}
public class ReferenceTransferTest{
public static void swap(DataWrap dw){
var tmp = dw.a;
dw.a = dw.b;
dw.b = tmp;
System.out.println("swap方法里,a成员变量的值是" + dw.a + ";b成员变量的值是" + dw.b);
}
public static void main(String []args){
var dw = new DataWrap();
dw.a = 6;
dw.b = 9;
swap(dw);
System.out.println("交换结束后,a成员变量的值是" + dw.a + ";b成员变量的值是" + dw.b);
}
}
以上代码,main()方法和swap()方法里的a、b成员变量的值都被交换了,这很容易产生一种错觉:调用swap方法时,传入swap()方法的就是dw对象本身,而不是它的复制品。但这是一种错觉。
程序从main()方法开始执行,main()方法开始创建了一个DataWrap对象,并定义了一个dw引用变量来指向DataWrap对象,这是一个与基本类型不同的地方。创建一个对象时,系统内存中有两个东西,堆内存保存了对象本身,栈内存中保存了指向该对象的引用变量。
接下来,调用swap()方法时,dw变量作为实参传入swap()方法,同样采用值传递方式:把main()方法里dw变量的值赋给swap()方法里的dw形参,从而完成了swap()方法的dw形参的初始化。值得指出的是,main()方法里的dw是一个引用(也就是一个指针),它保存了DataWrap对象的地址值,当把dw的值赋给swap()方法的dw形参后,即让swap()方法的dw形参也保存这个地址值,即也会引用到堆内存中的DataWrap对象。
所以系统赋值了dw变量,但并未复制DataWrap对象,此时不管操作main()方法里的dw变量,还是操作swap()方法里的dw参数,其实都是操作它们所引用的DataWrap对象,他们引用的是同一个对象。
形参个数可变的方法
import static java.lang.System.out;
//以可变个数形参来定义方法
public static void test(int a, String...books){
for (String book : books){
out.println(book);
}
}
test(5, "疯狂Java讲义", "轻量级Java EE企业应用实战");
传给books参数的实参数值其实也就等价于数组,也可以使用数组形式的传参 test(1,new String[]{"12321","3213213"}); 但是明显第一种形式更加简洁,但值得指出的是,数组形式的形参可以处于形参列表的任意位置,但个数可变的形参只能处于形参列表的最后。也就是说,一个方法最多只能有一个个数可变的形参。
递归方法
一个方法体内调用它自身,被称为方法递归。方法递归包含了一种隐式的循环,它会重复执行某段代码,但这种重复执行无需循环控制。
例如有如下数学题。已知有一个数列:f(0)=1,f(1)=4,f(n+2)=2*f(n+1)+f(n),其中n是大于0的整数,求f(10)的值。这个题可以用递归来求得。下面程序将定义一个fn方法,用于计算f(10)的值。
public class Recursive{
public static int fn(int n){
if(n == 0){
return 1;
}else if(n == 1){
return 4;
}else{
return 2*fn(n-1) + fn(n-2);
}
}
public static void main(String[] args){
System.out.println(fn(10));
}
}
当一个方法不断调用它本身时,必须在某个时刻方法的返回值是确定的,即不再调用它本身,否则这种递归就变成了无穷递归,类似于死循环。因此定义递归方法时,有一条最重要的规定:递归一定要向已知方向递归。
再来一题:
已知有一个数列:f(20) = 1,f(21)=4,f(n+2) = 2 * f(n+1) + f(n),其中n是大于0的整数,求f(10)的值。那么fn的方法体就应该改为如下:
public class Recursive{
public static int fn(int n){
if(n == 20){
return 1;
}else if(n == 21){
return 4;
}else{
return fn(n+2) - 2*fn(n+1);
}
}
public static void main(String[] args){
System.out.println(fn(10));
}
}
方法重载
Java允许同一个类里定义多个同名方法,只要形参列表不同就行。
没啥难度,如果被重载的方法里包含了个数可变的形参,则需要注意。
public class OverloadVarargs{
public void test(String msg){
System.out.println("只有一个字符串参数的test办法");
}
public void test(String...books){
System.out.println("****形参个数可变的test方法****");
}
public static void main(){
var olv = new OverloadVararges();
//下面三次将执行第二个test()方法
olv.test();
olv.test("aa","bb");
olv.test(new String[] {"aa"});
//下面调用将执行第一个test()方法
olv.test("aa");
}
}
大部分时候并不推荐重载形参个数可变的方法,因为这样做确实没有太大的意义,而且容易降低程序的可读性
成员变量和局部变量
成员变量被分为类变量和实例变量两种,定义成员变量时没有static修饰的就是实例变量,有static修饰的就是类变量。
局部变量根据定义形式的不同,又可以被分为如下三种。
形参:在定义方法签名时定义的变量,形参的作用域在整个方法内有效。
方法局部变量:在方法体内定义的局部变量,它的作用域是从定义该变量的地方生效,到该方法结束时失效。
代码块局部变量:在代码块中定义的局部变量,这个局部变量的作用域从定义该变量的地方生效,到该代码块结束时失效。
局部变量与成员变量不同的是,局部变量除了形参之外,都必须显示初始化。也就是说,必须先给方法局部变量和代码块局部变量指定初始值,否则不可以访问他们。
封装和隐藏
对一个类或对象实现良好的封装,可以实现以下目的:
- 隐藏类的实现细节
- 让使用者只能通过事先预定的方法来访问数据,从而可以在该方法里加入控制逻辑,限制对成员变量的不合理访问
- 可进行数据检查,从而有利于保证对象信息的完整性
- 便于修改,提高代码的可维护性。
为了实现良好的封装,需要从两个方面考虑:
- 把对象的成员变量和实现细节隐藏起来,不允许外部直接访问。
- 把方法暴露出来,让方法来控制对这些成员变量进行安全的访问和操作。
因此,封装实际上有两个方面的意义:把该隐藏的隐藏起来,把该暴露的暴露出来。这两个方面都需要通过使用Java提供的访问控制符来实现。
使用访问控制符
Java提供了3个访问控制符:private、protected、public,分别代表了3个访问控制级别,另外还有一个不加任何访问控制符的访问控制级别,提供了4个访问控制级别。Java的访问控制级别由小到大如图所示:
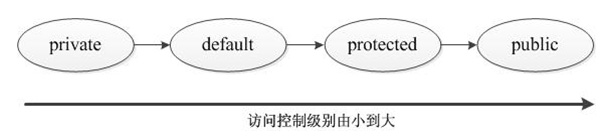
default并没有对应的访问控制符,当不使用任何访问控制符来修饰类或类成员,系统默认使用该访问控制级别。这4个访问控制级别的详细介绍如下。
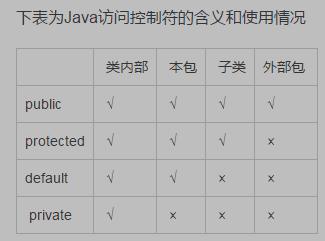
- private(当前类访问权限):如果类里的一个成员(包括成员变量、方法和构造器等)使用private访问控制符来修饰,则这个成员只能在当前类的内部被访问。很显然,这个访问控制符用于修饰成员变量最合适,使用它来修饰成员变量就可以把成员变量隐藏在该类的内部。
- default(包访问权限):如果类里的一个成员(包括成员变量、方法和构造器等)或者一个外部类不使用任何访问控制符来修饰,就称它是包访问权限的,default访问控制的成员或外部类可以被相同包下的其他类访问。
- protected(子类访问权限):如果一个成员(包括成员变量、方法和构造器等)使用protected访问控制符修饰,那么这个成员既可以被同一个包中的其他类访问,也可以被不同包中的子类访问。在通常情况下,如果使用protected来修饰一个方法,通常是希望其子类来重写这个方法。
- public(公共访问权限):这是一个最宽松的访问控制权限,如果一个成员(包括成员变量、方法和构造器等)或者一个外部类使用public访问控制符修饰,那么这个成员或外部类就可以被所有类访问,不管访问类和被访问类是否处于同一个包中,是否具有父子继承关系。
访问控制符用于控制一个类的成员是否可以被其他类访问,对于局部变量而言,其作用域就是它所在的方法,不可能被其他类访问,因此不能使用访问控制符来修饰。
但外部类只能有两种访问控制级别:public和默认,外部类不能使用private和protected修饰,因为外部类没有处于任何类的内部,也就没有其所在类的内部、所在类的子类两个范围,因此private和protected访问控制符对外部类没有意义
外部类可以使用public和包访问控制权限,使用public修饰的外部类可以被所有类使用,如声明变量、创建实例;不使用任何访问控制符来修饰的外部类只能被同一个包中的其他类使用。
- 类里的绝大部分成员变量都应该使用private修饰,只有一些static修饰的、类似全局变量的成员变量,才可能考虑使用public修饰。除此之外,有些方法只用于辅助实现该类的其他方法,这些方法被称为工具方法,工具方法也应该使用private修饰。
- 如果某个类主要用于其他类的父类,该类里的包含的大部分方法可能仅希望被其子类重写,而不想被外界直接调用,则应该使用protected修饰这些方法。
- 希望暴露出来给其他类自有调用的方法应该使用public修饰。因此,类的构造器通过使用public修饰,从而允许在其他地方创建该类的实例。因为外部类通常都希望被其他类自由使用,所以大部分外部类都使用public修饰。
package、import和import static
如果希望把一个类放在指定的包结构下,应该在Java源程序的第一个非注释行放置如下格式的代码:
package lee;
public class Hello{}
现在使用javac -d . Hello.java 会多出一个lee的文件夹,该文件夹下则有一个Hello.class文件
执行:java lee.Hello,当虚拟机要装载lee.Hello类时,它会依次搜索CLASSPATH环境变量所指定的系统路径,查找这些路径下是否包含lee路径,并在lee路径下查找是否包含Hello.class文件。
Java的包机制需要两个方面保证:①源文件里使用package语句指定包名;②class文件必须放在对应的路径下。
父包和自包在用法上则不存在任何关系,如果父包中的类需要使用子包中的类,则必须使用子包的全名,而不能省略父包部分。
JDK1.5以后增加了一种静态导入的语法,它用于导入指定类的某个静态成员变量、方法或全部的静态成员变量、方法。
import static java.lang.System.*;
import static java.lang.Math.*;
public class StaticImportTest{
public static void main(String[] args){
out.println(PI);
out.println(sqrt(256));
}
}
package语句 //0个或1个,必须放在文件开始
import | import static 语句 //0个或1个,必须放在所有类定义之前
public classDefinition | interfaceDefinition | enumDefinition //0个或1个public类、接口或枚举定义
classDefinition | interfaceDefinition | enumDefinition //0个或多个普通类、接口或枚举定义
深入构造器
使用构造器执行初始化
当创建一个对象时,系统为这个对象的实例变量进行默认初始化,这种默认的初始化把所有基本类型的实例变量设为0(对数值型实例变量)或false(对布尔类型实例变量),把所有引用类型的实例变量设为null。
如果想改变这种默认的初始化,想让系统创建对象时就为该对象的实例变量显示指定初始值,就可以通过构造器来实现。
如果程序员没有为Java类提供任何构造器,则系统会为这个类提供一个无参数的构造器,这个构造器的执行体为空,不做任何事情。无论如何,Java类至少包含一个构造器。
实际上,当程序员调用构造器时,系统会先为该对象分配内存空间,并为这个对象执行默认初始化,这个对象已经产生了——这些操作在构造器执行之前都完成了
构造器重载
下面代码实现了在一个构造器里直接使用另一个构造器的初始化代码
public class Apple{
public String name;
public String color;
public double weight;
public Apple(){
}
public Apple(String name, String color){
this.name = name;
this.color = color;
}
public Apple(String name, String color, double weight){
this(name,color);
this.weight = weight;
}
}
类的继承
继承的特点
Java使用extends作为继承的关键字,extends在英文中是拓展的意思,而不是继承!这个关键字很好的体现了子类和父类的关系,子类是对父类的拓展,子类是一种特殊的父类。从这个意义上来看,使用继承来描述子类和父类的关系是错误的,用扩展更恰当。
子类拓展了父类,将可以获得父类的全部成员变量、方法和内部类(包括内部接口、枚举),这与汉语中的继承(子辈从父辈那里获得一笔财富称为继承)具有很好的相似性。值得指出的是,Java的子类不能获得父类的构造器
Java语言摒弃了C++中难以理解的多继承特征,即每个类最多只有一个直接父类。
Java类只能有一个直接父类,但Java类可以有无限多个间接父类。例如Plant是Fruit的父类,Fruit是Apple的父类,那么Apple的直接父类就是Fruit,Apple的间接父类就是Plant。
重写父类的方法
不解释了,直接上图
public class Bird{
public void fly(){
System.out.println("我在天空里自由自在的飞翔");
}
}
public class Ostrich extends Bird{
public void fly(){
System.out.println("我只能在地上奔跑……");
}
public static void main(String[] args){
var os = new Ostrich();
os.fly(); //输出"我只能在地上奔跑"
}
}
尤其需要指出的是,覆盖方法和被覆盖方法要么都是类方法,要么都是实例方法,不能一个是类方法,一个是实例方法。例如,如下代码将会引发编译错误。
class BaseClass{
public static void test(){...}
}
public SubClas extends Base{
public void test(){...}
}
如果子类中定义了一个与父类private方法具有相同的方法名、相同的形参列表、相同的返回值类型的方法,依然不是重写,只是在子类中重新定义了一个新方法。例如,下面代码是完全正确的
class BaseClass{
//子类不可访问该方法
private void test(){...}
}
class SubClass extends BaseClass{
//此处不是方法重写,所以可以增加static关键字
public static void test(){...}
}
super限定
在子类定义的实例方法中可以通过super来访问父类中被隐藏的实例变量
class father{
public int a = 3;
}
public class son extends father{
private int a = 6;
public void accessOwner(){
System.out.println(a);
}
public void accessBase(){
System.out.println(super.a);
}
public static void main(String[] args){
son s = new son();
s.accessOwner();
s.accessBase();
}
}
如果在子类里没有包含和父类同名的成员变量,那么在子类实例方法中访问该成员变量时,则无需显示使用super或父类名作为调用者。如果在某个方法中访问名为a的成员变量,但没有显示指定调用者,则系统查找a的顺序为:
- 查找该方法中是否有名为a的局部变量。
- 查找当前类中是否包含名为a的成员变量。
- 查找a的直接父类中是否包含名为a的成员变量,依次上溯a的所有父类,直到java.lang.Object类,如果最终不能找到名为a的成员变量,则系统出现编译错误。
如果被覆盖的是类变量,在子类的方法中则可以通过父类名作为调用者来访问被覆盖的类变量。
如果在子类里定义了与父类中已有变量同名的变量,那么子类中定义的变量会隐藏父类中定义的变量。注意不是完全覆盖,因此系统在创建子类对象时,依然会为父类中定义的、被隐藏的变量分配内存空间。
因为只是简单隐藏了父类中的实例变量,所以会出现如下特殊的情形。
class father{
public int a = 3;
}
class son extends father{
private int a = 6;
}
public class test{
public static void main(String[] args){
son s = new son();
//程序不可访问s的私有变量a,所以下面语句将引起编译错误
// System.out.println(s.a);
//显示的向上转型
System.out.println(((father)s).a);
}
}
多态
多态性
先看下面程序。
class BaseClass{
public int book = 6;
public void base(){
System.out.println("父类的普通方法");
}
public void test(){
System.out.println("父类的被覆盖的方法");
}
}
public class SubClass extends BaseClass{
public String book = "轻量级JavaEE企业应用实战";
public void test(){
System.out.println("子类的覆盖父类的方法");
}
public void sub(){
System.out.println("子类的普通方法");
}
public static void main(String[] args) {
BaseClass bc = new BaseClass();
System.out.println(bc.book);
bc.base();
bc.test();
SubClass sc = new SubClass();
System.out.println(sc.book);
sc.base();
sc.test();
//调用父类里的方法,但是显示出子类的行为特征
BaseClass polymorphicBc = new SubClass();
System.out.println(polymorphicBc.book);
polymorphicBc.base();
polymorphicBc.test();
// polymorphicBc.sub()
}
}
可以简单理解成,表现出子类特征的父类。
第三个引用变量polymorphicBc则比较特殊,它的编译时类型是BaseClass,而运行时类型是SubClass,当调用该引用变量的test()方法(BaseClass类中定义了该方法,子类SubClass覆盖了父类的该方法)时,实际执行的是SubClasss类中覆盖后的test()方法,这就可能出现多态了。
因为子类其实是一个特殊的父类,因此Java允许把一个子类对象直接赋给一个父类引用变量,无需任何类型转换,或者被称为向上转型(upcasting),向上转型由系统自动完成。
当把一个子类对象直接赋给父类引用变量时,例如上面的BaseClass polymorphicBc = new SubClass();,这个polymorphicBc引用变量的编译时类型是BaseClass,而运行时类型是SubClass,当运行时调用该引用变量的方法时,其方法行为总是表现出子类方法的行为特征,而不是父类方法的行为特征,这就可能出现:相同类型的变量、调用同一个方法时呈现出多种不同的行为特征,这就是多态。
虽然polymorphicBc引用变量实际上确实包含sub()方法,(例如,可以通过反射来执行该方法),但因为它的编译时类型是BaseClass,因此编译时无法调用sub()方法。
与方法不同的是,对象的实例变量则不具备多态性。比如上面的polymorphicBc引用变量,程序中输出它的book实例变量时,并不是输出SubClass类里定义的实例变量,而是输出BaseClass类的实例变量。
通过引用变量来访问其包含的实例变量时,系统总是试图访问它编译时类型所定义的成员变量,而不是它运行时类型所定义的成员变量
使用var定义变量并不能改变变量的类型,因此使用var定义的变量同样会发生多态。例如,在上面的main方法中增加如下代码:
var v2 = polymorphic;
// 由于BaseClass类没有提供sub方法,所以下面代码编译会出现错误
v2.sub();
引用变量的强制类型转换
编写Java程序时,引用变量只能调用它编译时类型的方法,而不能调用它运行时类型的方法,即使它实际所引用的对象确实包含该方法。如果需要让这个引用变量调用它运行时类型的方法,则必须把他强制转换成运行时类型,强制类型转换需要借助于类型转换运算符-->(type)variable
类型转换运算符可以将一个基本类型变量转换成另一个类型,也可以将一个引用类型变量转换成其子类型。这种强制类型转换不是万能的,当进行强制类型转换时需要注意:
- 基本类型之间的转换只能在数值类型之间进行,这里说的数值类型包括整数型、字符型和浮点型。但数值类型和布尔类型之间不能进行类型转换。
- 引用类型之间的转换只能在具有继承关系的两个类型之间进行,如果是两个没有任何继承关系的类型,则无法进行类型转换,否则编译时就会出现错误。如果试图把一个父类实例转换成子类类型,则这个对象必须实际上是子类实例才行(即编译时类型是父类类型,而运行时类型是子类类型),否则将在运行时引发ClassCastException异常。
public class ConversionTest{
public static void main(String[] args){
var d = 13.4;
var l = (long)d;
System.out.println(l);
var in = 5;
//试图把一个数值类型的变量转换为boolean类型,下面代码编译出错
//编译时会提示:不可转换的类型
//var b = (boolean) in;
Object obj = "Hello";
//obj 变量的编译时类型为Object,Object与String存在继承关系,可以强制类型转换
//而且obj变量的实际类型是String,所以运行时也通过
var objStr = (String) obj;
System.out.println(objStr);
//定义一个objPri变量,编译时类型为Object,实际类型为Integer
Object objPri = Integer.valueOf(5);
//objPri变量的编译时类型为Object,objPri的运行时类型为Integer
//Object 与 Integer存在继承关系
//可以强制类型转换,而objPri变量的实际类型是Integer
//所以下面代码运行时引发ClassCastException异常
var str = (String) objPri;
}
}
考虑到进行强制类型转换时可能出现异常,因此进行类型转换之前应先通过instanceof运算符来判断是否可以成功转换。例如,上面的var str = (String)objPri;代码运行时会引发ClassCastException异常,是因为objPri不可转换成String类型。为了让程序更加健壮,可以将代码改为如下:
if(objPri instanceof String){
var str = (String)objPri;
}
当把子类对象赋给父类引用变量,被称为向上转型(upcasting),这种转型总是可以成功的,这也从另一个侧面证明了子类是一种特殊的父类。这种转型只是表明这个引用变量的编译时类型是父类,但实际执行它的方法时,依然表现出子类对象的行为方式。但把一个父类对象赋给子类引用变量时,就需要强制类型转换,而且还可能在运行时产生ClassCastException异常,使用instanceof运算符可以让强制类型转换更安全。
instanceof运算符
instanceof运算符的前一个操作数通常是一个引用类型变量,后一个操作数通常是一个类(也可以是接口,可以把接口理解成一个特殊的类),它用于判断前面的对象是否是后面的类,或者其子类,实现类的实例。如果是,则返回true,否则返回false。
在使用instanceof运算符时需要注意:instanceof运算符前面操作数的编译时类型要么与后面的类相同,要么与后面的类具有父子继承关系,否则会引发编译错误。下面程序示范了instanceof运算符的用法。
public class InstanceofTest {
public static void main(String[] args) {
//声明hello时使用Object类,则hello的编译类型是Object
//Object是所有类的父类,但hello变量的实际类型是String
Object hello = "Hello";
//String与Object类存在继承关系,可以进行instanceof运算。返回true
System.out.println("字符串是否是Object类的实例:"+(hello instanceof Object));
System.out.println("字符串是否是String类的实例:"+(hello instanceof String));
//Math与Object类存在继承关系,可以进行instanceof运算。返回false
System.out.println(hello instanceof Math);
//String实现了Comparable接口,所以返回true
System.out.println(hello instanceof Comparable);
var a = "Hello";
//String类与Math类没有继承关系,所以下面代码编译无法通过
//System.out.println("字符串是否是Math类的实例"+ (a instanceof Math));
}
}
instanceof运算符的作用是:在进行强制类型转换之前,首先判断前一个对象是否是后一个类的实例,是否可以成功转换,从而保证代码更加健壮。
继承与组合
使用继承的注意点
继承带来了高度复用的同时,也带来了一个严重的问题:继承严重地破坏了父类的封装性。
为了保证父类有良好的封装性,不会被子类随意改变,设计父类通常应该遵循如下规则。
- 尽量隐藏父类的内部数据。尽量把父类的所有成员变量都设置成private访问类型,不要让子类直接访问父类的成员变量
- 不要让子类可以随意访问、修改父类的方法。父类中那些仅为辅助其他的工具方法,应该使用private访问控制符修饰,让子类无法访问该方法;如果父类中的方法需要被外部类调用,则必须以public修饰,但又不希望子类重写该方法,可以使用final修饰符来修饰该方法;如果希望父类的某个方法被子类重写,但不希望被其他类访问,则可以使用protected来修饰该方法。
- 尽量不要在父类构造器中调用将要被子类重写的方法。
利用组合实现复用
对于继承而言,子类可以直接获得父类的public方法,程序使用子类时,将可以直接访问该子类从父类那里继承到的方法;而组合则是把旧类对象作为新类的成员变量组合进来,用以实现新类的功能,用户看到的是新类的方法,而不能看到被组合对象的方法。因此,通常需要在新类里使用private修饰被组合的旧类对象。
class Animal {
private void beat() {
System.out.println("心脏跳动……");
}
public void breathe() {
beat();
System.out.println("吸一口气,吐一口气,呼吸中……");
}
}
class Bird extends Animal {
public void fly() {
System.out.println("我在天空自在的飞翔……");
}
}
class Wolf extends Animal {
public void run() {
System.out.println("我在陆地上的快速奔跑");
}
}
public class InheritTest {
public static void main(String[] args) {
var b = new Bird();
b.breathe();
b.fly();
var w = new Wolf();
w.breathe();
w.run();
}
}
下面展示一下组合的方法,也可实现相同的复用。
class Animal {
private void beat() {
System.out.println("心脏跳动……");
}
public void breathe() {
beat();
System.out.println("吸一口气,吐一口气,呼吸中……");
}
}
class Bird{
private Animal a;
public Bird(Animal a){
this.a = a;
}
public void breathe(){
a.breathe();
}
public void fly(){
System.out.println("我在天空中自在的飞翔……");
}
}
class Wolf{
private Animal a;
public Wolf(Animal a){
this.a = a;
}
public void breathe(){
a.breathe();
}
public void run(){
System.out.println("我在陆地上的快速奔跑……");
}
}
public class CompositeTest {
public static void main(String[] args) {
var a1 = new Animal();
var b = new Bird(a1);
b.breathe();
b.fly();
var a2 = new Animal();
var w = new Wolf(a2);
w.breathe();
w.run();
}
}
组合相对于继承只是多个一个引用变量来引入被嵌入子类的对象,所以继承设计与组合设计的系统开销不会有本质的差别。
初始化块
Java使用构造器来对单个对象进行初始化操作,使用构造器先完成整个Java对象的状态初始化,然后将Java对象返回给程序,从而让该Java对象的信息更加完整。与构造器作用非常相似的是初始化块,它也可以对Java对象进行初始化操作。
使用初始化块
初始化块的修饰符只能是static,使用static修饰的初始化块被称为类初始化块(静态初始化块),没有static修饰的初始化块被称为实例初始化块(非静态初始化块)。初始化块里的代码可以包括任何可执行性语句,包括定义局部变量、调用其他对象的方法,以及使用分支、循环语句等。
下面程序定义了一个Person类,它既包含了构造器,也包含了实例初始化块。下面看看在程序中创建Person对象时发生了什么。
public class Person{
//下面定义一个实例初始化块
{
var a = 6;
if(a > 4){
System.out.println("Person实例初始化块:局部变量a的值大于4");
}
System.out.println("Person的实例初始化块");
}
//定义第二个实例初始化块
{
System.out.println("Person的第二个实例初始化块");
}
//定义无参数的构造器
public Person(){
System.out.println("Person类的无参数构造器");
}
}
程序的输出如下:
Person实例初始化块,局部变量a的值大于4
Person的实例初始化块
Person的第二个实例初始化块
Person类的无参数构造器
虽然Java允许一个类里定义2个实例初始化块,但这没有任何意义。因为实例初始化是在创建Java对象时隐式执行的,而且它们总是全部执行,因为完全可以把多个实例初始化块合并成一个实例初始化块,从而可以让程序更加简洁,可读性更强
实例初始化块、声明实例变量指定的默认值都可认为是对象的初始化代码,它们的执行顺序与源程序中的排列顺序相同。看如下代码
public class InstanceInitTest {
{
a = 6;
}
int a = 9;
//下面代码将输出9
public static void main(String[] args) {
System.out.println(new InstanceInitTest().a);
}
}
当Java创建一个对象时,系统先为该对象的所有实例变量分配内存(前提是该类已经被加载过了),接着程序开始对这些实例变量执行初始化,其初始化顺序是:先执行实例初始化块或声明实例变量时指定的初始值(这两个地方指定初始值的执行顺序与它们在源代码中的排列顺序相同),再执行构造器里执行的初始值。
实例初始化块和构造器
实例初始化块总是在构造器执行之前执行。系统同样可使用实例初始化块来进行对象的初始化操作。
与构造器不同的是,实例初始化块是一段固定的代码,它不能接收任何参数。
如果有一段初始化代码对所有对象完全相同,且无须接收任何参数,就可以把这段初始化处理代码提取到实例初始化块中。
实际上实例初始化块是一个假象,使用javac命令编译Java类后,该Java类中的实例初始化块会消失——实例初始化块中代码会被"还原"到每个构造器中,且位于构造器所有代码前面
与构造器类似,创建一个Java对象时,不仅会执行该类的实例初始化块和构造器,而且系统会一直上溯到java.lang.Object类,先执行java.lang.Object类的实例初始化块,开始执行java.lang.Object的构造器,依次向下执行其父类的实例初始化块,开始执行其父类的构造器……最后才执行该类的实例初始化块和构造器,返回该类的对象。
除此之外,如果希望类加载后就对整个类进行初始化操作,就需要static关键词来修饰初始化块。
类初始化块
类初始化是类相关的,系统在类初始化阶段执行类初始化块,而不是在创建对象时才执行。因此类初始化块总是比实例初始化块先执行。类初始化块用于对整个类进行初始化处理,通常用于对类变量执行初始化处理。类初始化块不能对实例变量进行初始化处理。
与实例初始化块类似的是,系统在类初始化阶段执行类初始化块时,不仅会执行本类的类初始化块,而且还会一直上溯到java.lang.Object类(如果它包含类初始化块),先执行java.lang.Object类的类初始化块(如果有),然后执行其父类的类初始化块……最后才执行该类的类初始化块,经过这个过程,才完成了该类的初始化过程。只有当类初始化完成后,才可以在系统中使用这个类,包括访问这个类的类方法、类变量或者用这个类来创建实例。
package aa;
class Root {
static {
System.out.println("Root的类初始化块");
}
{
System.out.println("Root的实例初始化块");
}
public Root(){
System.out.println("Root的无参数的构造器");
}
}
class Mid extends Root{
static {
System.out.println("Mid的类初始化块");
}
{
System.out.println("Mid的实例初始化块");
}
public Mid(){
System.out.println("Mid的无参数的构造器");
}
public Mid(String msg){
System.out.println("Mid的带参数构造器,其参数值:"+msg);
}
}
class Leaf extends Mid{
static {
System.out.println("Leaf的类初始化块");
}
{
System.out.println("Leaf的实例初始化块");
}
public Leaf(){
super("疯狂Java讲义");
System.out.println("执行Leaf的构造器");
}
}
public class Test{
public static void main(String[] args) {
new Leaf();
new Leaf();
}
}
话不多说,执行结果说明了一切
Root的类初始化块
Mid的类初始化块
Leaf的类初始化块
Root的实例初始化块
Root的无参数的构造器
Mid的实例初始化块
Mid的带参数构造器,其参数值:疯狂Java讲义
Leaf的实例初始化块
执行Leaf的构造器
Root的实例初始化块
Root的无参数的构造器
Mid的实例初始化块
Mid的带参数构造器,其参数值:疯狂Java讲义
Leaf的实例初始化块
执行Leaf的构造器
Java系统加载并初始化某个类时,总是保证该类的所有父类(包括直接父类和间接父类)全部加载并初始化。
类初始化块和声明类变量时所指定的初始值都是该类的初始化代码,它们的执行顺序与源程序中的排列顺序相同。
public class StaticInitTest {
static{
a = 6;
}
static int a = 9;
public static void main(String[] args) {
//下面结果将输出9
System.out.println(StaticInitTest.a);
}
}
当JVM第一次主动使用某个类时,系统会在类准备阶段为该类的所有类变量分配内存;在初始化阶段则负责初始化这些类变量,初始化类变量就是执行类初始化块代码和声明类变量时指定的初始值,它们的执行顺序与源代码中的排列顺序相同。
面向对象(下)
包装类
Java是面向对象的编程语言,但他也包含了8种基本数据类型,这8种基本数据类型不支持面向对象的编程机制,也不具备"对象"的特征:没有成员变量、方法可以被调用。Java之所以提供这8种基本数据类型,主要是为了照顾程序员的传统习惯。
这8种数据类型带来了一定的方便性,例如可以进行简单、有效的常规数据处理。但在某些时候,基本数据类型会有一些制约,例如所有引用类型的变量都继承了Object类,都可当成Obeject类型变量使用。但基本数据类型变量就不可以,如果有个方法需要Object类型的参数,但实际需要的值却是2、3等数值,这可能就比较难处理。
为了解决8种基本数据类型的变量不能当成Object类型变量使用的问题,Java提供了包装类(Wrapper Class)的概念,为8种基本数据类型分别定义了相应的引用类型,并称之为基本数据类型的包装类。
| 基本数据类型 | 大小 | 默认值 | 包装数据类型 |
|---|---|---|---|
| byte | 8bit | 0 | Byte |
| short | 16bit | 0 | Short |
| int | 32bit | 0 | Integer |
| long | 64bit | 0L | Long |
| float | 32bit | 0.0f | Float |
| double | 64bit | 0.0d | Double |
| char | 16bit | \u0000 | Character |
| boolean | / | false | Boolean |
在JDK1.5以前,把基本数据类型变量变成包装类实例需要通过对应包装类的valueOf()静态方法来实现。在JDK1.5以前,如果希望获得包装类对象中包装的基本类型变量,则可以使用包装类提供的xxxValue()实例犯法。由于这种用法已经过时,故此处不再给出实例代码。
从JDK1.5以后,提供了自动装箱(Autoboxing)和自动拆箱(AutoUnboxing)功能。所谓自动装箱,就是可以把一个基本类型变量直接赋给对应的包装类变量,或者赋给Object变量(Object是所有类的父类,子类对象可以直接赋给父类变量):自动拆箱则与之相反,允许直接把包装类对象直接赋给一个对应的基本类型变量。
下面程序示范了自动装箱和自动拆箱的用法。
public class AutoBoxingUnboxing{
public static void main(String[]args){
//直接把一个基本类型变量赋给Integer对象
Integer inObj = 5;
//直接把一个boolean类型变量赋给一个Object类型的变量
Object boolObj = true;
//直接把一个Integer对象赋给int类型的变量
int it = inObj;
if(boolObj instanceof Boolean){
//先把Object对象强制类型转换为Boolean类型,再赋给boolean变量
boolean b = (Boolean) boolObj;
System.out.println(b);
}
}
}
下面介绍一个Integer中自动装箱很有意思的坑,重点!
//通过自动装箱,允许把基本类型值赋给包装类实例
Integer ina = 2;
Integer inb = 2;
System.out.println("两个2自动装箱后是否相等:" + (ina == inb)); //输出true
Integer biga = 128;
Integer bigb = 128;
System.out.println("两个128自动装箱后是否相等:" + (biga == bigb)); //输出false
出现结果不同的原因与Integer类的设计有关,查看Java系统中java.lang.Integer类的源代码,如下所示
static final Integer[] cache = new Integer((-128)+127+1);
static{
//执行初始化,创建-128到127的Integer实例,并放入cache数组中
for(int i = 0; i < cache.length ; i++){
cache[i] = new Integer(i - 128);
}
}
从上面代码可以看出,系统把一个-128~127之间的整数自动装箱成Integer实例,并放入了一个名为cache的数组中缓存起来。如果以后把一个-128~127之间的整数自动装箱成一个Integer实例时,实际上是直接指向对应的数组元素,因此-128~127之间的同一个整数自动装箱成Integer实例时,永远都是引用cache数组的同一个数组元素,所以他们全部相等;但每次把一个不在-127~128范围内的整数自动装箱成Integer实例时,系统总是重新创建一个Integer实例,所以出现程序中的运行结果。
Java7增强了包装类的功能,Java7为所有的包装类都提供了一个静态的compare(xxx val1, xxx val2)方法,这样开发者就可以通过包装类提供的compare(xxx val1, xxx val2)方法来比较两个基本类型值的大小,包括比较两个boolean类型值,两个boolean类型值进行比较时,true>false。
System.out.println(Boolean.compare(true,false)); //输出1
System.out.println(Boolean.compare(true,true)); //输出0
System.out.println(Boolean.compare(false,true)); //输出-1
不仅如此,Java还为Character包装类增加了大量的工具方法来对一个字符进行判断。Java8再次增强了这些包装类的功能。其中一个重要的增强就是支持无符号算术运算。Java8为整型包装类(Byte、Short、Integer、Long)增加了支持无符号运算的方法。
public class UnsignedTest {
public static void main(String[] args) {
byte b = -3;
//将byte类型的-3转换成无符号整数
System.out.println("byte类型的-3对应的无符号整数:" + Byte.toUnsignedInt(b)); //输出253
//使用十六进制解析无符号整数
var val = Integer.parseUnsignedInt("ab",16);
System.out.println(val); //输出171
//将-12转换为无符号int型,然后转换为十六进制的字符串
System.out.println(Integer.toUnsignedString(-12,16));
//将两个数转换为无符号整数后相除
System.out.println(Integer.divideUnsigned(-2,3));
//将两个数转换为无符号整数相除后求余
System.out.println(Integer.remainderUnsigned(-2,7));
}
}
类成员
理解类成员
当系统第一次准备使用该类时,系统会为该类变量分配内存空间,类变量开始生效,直到该类被卸载,该类的类变量所占有的内存才被系统的垃圾回收机制回收。类变量生存范围几乎等同于该类的生存范围。当类初始化完成后,类变量也被初始化完成。
类变量既可以通过类来访问,也可通过类的对象来访问。但通过累的对象来访问类变量时,实际上并不是访问该对象所拥有的变量,因为当系统创建该类的对象时,系统不会再为类变量分配内存,也不会再次对类变量进行初始化,也就是说,对象根本不拥有对应类的类变量。通过对象访问类变量只是一种幻觉,通过对象访问的依然是该类的类变量,可以这样理解,当通过对象来访问类变量时,系统会在底层转换为通过该类来访问类变量。
因此即使某个实例为null,它也可以访问它所属类的类成员。例如如下代码:
public class NullAccessStatic {
private static void test(){
System.out.println("static修饰的类方法");
}
public static void main(String[] args) {
NullAccessStatic nas = null;
nas.test();
}
}
对static关键字而言,有一条非常重要的规则:类成员(包括成员变量、方法、初始化块、内部类和内部枚举)不能访问实例成员(包括成员变量、方法、初始化块、内部类和内部枚举)。因为类成员是属于类的,类成员的作用域比实例成员的作用域更大,完全可能出现类成员已经初始化完成,但实例成员还不曾初始化的情况,如果允许类成员访问实例成员将会引起大量错误。
单例类
package aa;
class Singleton{
private static Singleton instance;
private Singleton(){}
public static Singleton getInstance(){
if (instance==null){
instance = new Singleton();
}
return instance;
}
}
public class SingletonTest {
public static void main(String[] args) {
Singleton s1 = Singleton.getInstance();
Singleton s2 = Singleton.getInstance();
System.out.println(s1 == s2);
}
}
final修饰符
final修饰的不可被改变,一旦获得了初始值,该final变量的值就不能被重新赋值,因此final修饰成员变量和修饰局部变量时有一定的不同。
final成员变量
对于final修饰的成员变量而言,一旦有了初始值,就不能被重新赋值,如果既没有在定义成员变量时指定初始值,也没有在初始化块、构造器中为成员变量指定初始值,那么这些成员变量的值将一直是系统默认分配的0、'\u0000'、false或null,这些成员变量也就完全失去了存在的意义。因此Java语法规定:final修饰的成员变量必须由程序员显式地指定初始值。
归纳起来:final修饰的类变量、实例变量能指定初始值的地方如下。
- 类变量:必须在静态初始化块中指定初始值或声明该类变量时指定初始值,而且只能在两个地方的其中之一指定。
- 实例变量:必须在非静态初始化块、声明该实例变量或构造器中指定初始值,而且只能在三个地方的其中之一指定。
如果打算在构造器、初始化块中对final成员变量进行初始化,则不要在初始化之前就访问final成员变量;否则,由于Java允许通过方法来访问final成员变量,此时将看到系统将final成员变量默认初始化为0(或'\u0000'、false或null)的情况。例如如下示例程序。
public class FinalErrorTest {
//系统不会对final成员变量进行默认初始化
final int age;
{
//age没有初始化,所以此处代码将引起错误
//System.out.println(age); //①
printAge(); //②
age = 6;
System.out.println(age);
}
public void printAge(){
System.out.println(age);
}
public static void main(String[] args) {
new FinalErrorTest();
}
}
Java不允许在final成员变量显示初始化之前,直接访问final修饰的age成员变量,所以初始化块中①代码将引起错误;但②代码通过方法来访问final修饰的age成员变量,此时又是允许的,此处将看到输出0。但这显然违背了final成员变量的设计初衷:对于final成员变量,程序当然希望总是能访问到它固定的、显示初始化的值。
final成员变量在显示初始化之前不能直接访问,但可以通过方法来访问,这基本上可断定是Java设计的一个缺陷。按照正常逻辑,final成员变量在显示初始化之前是不应该允许被访问的。因此,建议Java开发者尽量避免在final成员变量初始化之前访问它。
final修饰基本类型变量和引用类型变量的区别
下面程序示范了final修饰数组和Person对象的情形。
import java.util.Arrays;
class Person{
private int age;
public Person(){}
public Person(int age){
this.age = age;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
public class FinalReferenceTest {
public static void main(String[] args) {
//final修饰数组变量,iArr是一个引用变量
final int[] iArr = {5,6,12,9};
System.out.println(Arrays.toString(iArr));
//对数组元素进行排序,合法
Arrays.sort(iArr);
System.out.println(Arrays.toString(iArr));
//对数组元素赋值,合法
iArr[2] = -8;
System.out.println(Arrays.toString(iArr));
//下面语句对iArr重新赋值,非法
//iArr = null;
//final修饰Person变量,p是一个引用变量
final var p = new Person(45);
//改变Person对象的age实例变量,合法
p.setAge(23);
System.out.println(p.getAge());
// p = null;
}
}
使用final修饰的引用类型变量不能被重新赋值,但可以改变引用变量所引用对象的内容。
可执行"宏变量"的final变量
对一个final变量来说,不管它是类变量、实例变量,还是局部变量,只要该变量满足三个条件,这个final变量就不再是一个变量,而是一个直接量。
- 使用final修饰符修饰。
- 在定义该final变量时指定了初始值。
- 该初始值可以在编译时就被确定下来。
看如下程序:
public class FinalLocalTest{
public static void main(String[] args){
//定义一个普通局部变量
final var a = 5;
System.out.println(a);
}
}
对于这个程序来说,变量a其实根本不存在,当程序执行System.out.println(a);代码时,实际转换为执行System.out.println(5);
final修饰符的一个重要用途就是定义"宏变量"。当定义final变量时就为该变量指定了初始值,而且该初始值可以在编译时就确定下来,那么这个final变量本质上就是一个"宏变量",编译器会把程序中所有用到该变量的地方直接替换成该变量的值。
final方法
下面程序试图重写final方法,将会引发编译错误。
public class FinalMethodTest{
public final void test(){}
}
class Sub extends FinalMethodTest{
//下面方法定义将出现编译错误,不能重写final方法
public void test(){}
}
下面程序示范了如何在子类中"重写"父类的private final方法。
public class PrivateFinalMethodTest{
private final void test();
}
class Sub extends PrivateFinalMethodTest{
//下面的方法定义不会出现问题
public void test(){}
}
final修饰的方法仅仅是不能被重写,并不是不能被重载,因此下面程序完全没有问题。
public class FinalOverload{
//final修饰的方法只是不能被重写,完全可以被重载
public final void test(){}
public final void test(String arg){}
}
final类
final修饰的类不可以有子类,例如java.lang.Math类就是一个final类,它不可以有子类。为了保证某个类不可被继承,则可以使用final修饰这个方法。
不可变类
下面定义一个不可变的Address类,程序把Address类的detail和postCode成员变量都使用private隐藏起来,并使用final修饰这两个成员变量,不允许其他方法修改这两个成员变量的值。
import java.util.Objects;
public class Address {
private final String detail;
private final String postCode;
public Address(String detail,String postCode){
this.detail = detail;
this.postCode = postCode;
}
public String getDetail() {
return detail;
}
public String getPostCode() {
return postCode;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Address address = (Address) o;
return Objects.equals(detail, address.detail) && Objects.equals(postCode, address.postCode);
}
public int hashCode() {
return Objects.hash(detail, postCode);
}
}
与不可变类对应的是可变类,可变类的含义是该类的实例变量的值是可变的。大部分时候所创建的类都是可变类,特别是JavaBean,因为总是为其实例变量提供了setter和getter方法。
下面程序试图定义一个不可变的Person类,但因为Person类包含一个引用类型的成员变量,且这个引用类时是可变类,所以导致Person类也变成了可变类。
class Name{
private String firstName;
private String lastName;
public Name(){}
public Name(String firstName, String lastName){
this.firstName = firstName;
this.lastName = lastName;
}
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
}
public class Person {
private final Name name;
public Person(Name name){
this.name = name;
}
public Name getName(){
return name;
}
public static void main(String[] args) {
var n = new Name("悟空","孙");
var p = new Person(n);
//Person对象的name的firstName值为"悟空"
System.out.println(p.getName().getFirstName());
//改变Person对象的name的firstName值
n.setFirstName("八戒");
//Person对象的name的firstName值被改为"八戒"
System.out.println(p.getName().getFirstName());
}
}
上面程序中n.setFirstName("八戒");修改了Name对象(可变类的实例)的firstName的值,但由于Person类的name实例变量引用了该Name对象,这就会导致Person对象的name的firstName会被改变,这就破坏了设计Person类的初衷。
为了保持Person对象的不可变性,必须保护好Person对象的引用类型的成员变量:name,让程序无法访问到Person对象的name成员变量,也就无法利用name成员变量的可变性来改变Person对象了。为此将Person类改为如下:
public class Person{
private final Name name;
public Person(Name name){
// 设置 name 实例变量为临时创建的Name对象,该对象的firstName和lastName
//与传入的name参数的firstName和lastName相同
this.name = new Name(name.getFirstName(),name.getLastName());
}
public Name getName(){
//返回一个匿名对象
return new Name(name.getFirstName(),name.getLastName());
}
}
因此,如果需要设计一个不可变类,尤其要注意其引用类型的成员变量,如果引用类型的成员变量的类是可变的,就必须采取必要的措施来保护该成员变量所引用的对象不会被修改,这样才能创建真正的不可变类。
缓存实例的不可变类
不可变类的实例状态不可改变,可以很方便的被多个对象所共享。如果程序经常需要使用相同的不可变类实例,则应该考虑缓存这种不可变类的实例。毕竟重复创建相同的对象没有太大的意义,而且加大系统开销。如果可能,应该将已经创建的不可变类的实例进行缓存。
缓存是软件设计中一个非常有用的模式,缓存的实现方式有很多种,不同的实现方式可能存在较大的性能差别,关于缓存的性能问题此处不做深入讨论。
本节将使用一个数组来作为缓存池,从而实现一个缓存实例的不可变类。
package aa;
class CacheImmutale{
private static int MAX_SIZE = 10;
private static CacheImmutale[] cache = new CacheImmutale[MAX_SIZE];
private static int pos = 0;
private final String name;
private CacheImmutale(String name){
this.name = name;
}
public String getName(){
return name;
}
public static CacheImmutale valueOf(String name){
for (int i=0 ; i<cache.length;i++){
if (cache[i].getName().equals(name)){
return cache[i];
}
}
if (pos == MAX_SIZE){
cache[0] = new CacheImmutale(name);
pos = 1;
}else{
cache[pos++] = new CacheImmutale(name);
}
return cache[pos-1];
}
public boolean equals(Object obj){
if (this == obj){
return true;
}
if (obj != null && obj.getClass() == CacheImmutale.class){
var ci = (CacheImmutale)obj;
return name.equals(ci.getName());
}
return false;
}
public int hashCode(){
return name.hashCode();
}
}
public class CacheImmutaleTest {
public static void main(String[] args) {
var c1 = CacheImmutale.valueOf("hello");
var c2 = CacheImmutale.valueOf("hello");
System.out.println(c1 == c2);
}
}
是否需要隐藏CacheImmutale类的构造器完全取决于系统需求,盲目乱用缓存也可能导致系统性能下降,缓存的对象会占用系统内存,如果某个对象只使用一次,重复使用的概率不大,缓存该实例就弊大于利;反之,如果某个对象需要频繁地重复使用,缓存该实例就利大于弊。
例如Java提供的java.lang.Integer类,他就采用了与CacheImmulate类相同的处理策略,如果采用的new构造器来创建Integer对象,则每次返回全新的Integer对象;如果采用valueOf()方法来创建Integer对象,则会缓存该方法创建的对象。下面程序示范了Integer类构造器和valueOf()方法存在的差异
由于通过new构造器创建Integer对象不会启用缓存,因此性能较差,Java9已经将该构造器标记为过时。
public class IntegerCacheTest {
public static void main(String[] args) {
var in1 = new Integer(6);
var in2 = Integer.valueOf(6);
var in3 =Integer.valueOf(6);
System.out.println(in1 == in2); //false
System.out.println(in2 == in3); //true
var in4 =Integer.valueOf(200);
var in5 = Integer.valueOf(200);
System.out.println(in4 == in5); //false
}
}
抽象类
抽象方法是只有方法签名,没有方法实现的方法。
抽象方法和抽象类
抽象方法和抽象类必须使用abstract修饰符来定义,有抽象方法的类只能被定义成抽象类,抽象类里可以没有抽象方法。
- 抽象类必须使用abstract修饰符来修饰,抽象方法也必须使用abstract修饰符来修饰,抽象方法不能有方法体。
- 抽象类不能被实例化,无法使用new关键字来调用抽象类的构造器创建抽象类的实例。即使抽象类里不包含抽象方法,这个抽象类也不能创建实例。
- 抽象类可以包含成员变量、方法(普通方法和抽象方法都可以)、构造器、初始化块、内部类(接口、枚举)5种成分。抽象类的构造器不能用于创建实例,主要是用于被其子类调用。
- 含有抽象方法的类(包括直接定义了一个抽象方法;或继承了一个抽象父类,但没有完全实现父类包含的抽象方法;或实现了一个接口,但没有完全实现接口包含的抽象方法三种情况)只能被定义成抽象类。
总结起来,抽象类有得有失,"得"指的是抽象类多了一个能力:抽象类可以包含抽象方法。"失"指的是抽象类失去了一个能力:抽象类不能用于创建实例。
下面定义一个Shape抽象类
public abstract class Shape {
{
System.out.println("执行Sharp的初始化块");
}
private String color;
public abstract double calPerimeter();
public abstract String getType();
public Shape(){
}
public Shape(String color){
System.out.println("执行Shape的构造器……");
this.color = color;
}
public String getColor() {
return color;
}
public void setColor(String color) {
this.color = color;
}
}
抽象类不能用于创建实例,只能当做父类被其他子类继承。
继承抽象类,必须实现Shape类里的所有抽象方法。
public class Triangle extends Shape{
private double a;
private double b;
private double c;
public Triangle(String color,double a, double b, double c){
super(color);
this.setSides(a,b,c);
}
public void setSides(double a, double b ,double c){
if (a >= b+c || b>=a+c || c>= a+b){
System.out.println("三角形两边之和必须大于第三边");
return;
}
this.a = a;
this.b = b;
this.c = c;
}
public double calPerimeter() {
return a+b+c;
}
public String getType() {
return "三角形";
}
}
public class Circle extends Shape{
private double radius;
public Circle(String color , double radius){
super(color);
this.radius = radius;
}
public void setRadius(double radius){
this.radius = radius;
}
public double calPerimeter() {
return 2 * Math.PI * radius;
}
public String getType() {
return getColor()+"圆形";
}
public static void main(String[] args) {
Shape s1 = new Triangle("黑色",3,4,5);
Shape s2 = new Circle("黄色",3);
System.out.println(s1.getType());
System.out.println(s1.calPerimeter());
System.out.println(s2.getType());
System.out.println(s2.calPerimeter());
}
}
利用抽象类和抽象方法的优势,可以更好地发挥多态的优势,使得程序更加灵活。
①abstract:有抽象方法,那么一定是抽象类。因为抽象方法的目的就是让其子类进行实现,②final:final修饰的东西不能被修改,不能被继承③它们是处于一个互斥的意义,当二者同时修饰于一种东西(无论是类,还是方法)上,则会报错,总结:abstract和final不能共生!
abstract不能用于修饰成员变量,不能用于修饰局部变量,即没有抽象变量、没有抽象成员变量等说法;abstract也不能用于修饰构造器,没有抽象构造器,抽象类里定义的构造器只能是普通构造器。
除此之外,当使用static修饰一个方法时,表明这个方法属于该类本身,即通过类就可调用该方法,但如果该方法被定义成抽象方法,则将导致通过该类来调用该方法时出现错误(调用了一个没有方法体的方法肯定会引起错误)。因此static和abstract不能同时修饰某个方法,即没有所谓的类抽象方法。
static和abstract并不是绝对互斥的,static和abstract虽然不能同时修饰某个方法,但它们可以同时修饰内部类。
abstract关键字修饰的方法必须被子类重写才有意义,否则这个方法将永远不会有方法体,因此abstract方法不能定义为private访问权限,即private和abstract不能同时修饰方法。
抽象类的作用
以抽象类作为子类的模板,从而避免了子类设计的随意性。
抽象类体现的就是一种模板模式的设计,抽象类作为多个子类的通用模板,子类在抽象类的基础上进行拓展、改造,但子类总体上会大致保留抽象类的行为方式。
例如前面的Shape、Circle和Triangle三个类,已经使用了模板模式。下面再介绍一个模板模式的范例,在这个范例的抽象父类中,父类的普通方法依赖于一个抽象方法,而抽象方法则推迟到子类中提供实现。
public abstract class SpeedMeter {
private double turnRate;
public SpeedMeter(){}
public abstract double calGirth();
public void setTurnRate(double turnRate){
this.turnRate = turnRate;
}
//定义速度的通用算法
public double getSpeed(){
return calGirth()*turnRate;
}
}
public class CarSpeedMeter extends SpeedMeter{
private double radius;
public CarSpeedMeter(double radius){
this.radius = radius;
}
@Override
public double calGirth() {
return radius*2*Math.PI;
}
public static void main(String[] args) {
var csm = new CarSpeedMeter(0.34);
csm.setTurnRate(15);
System.out.println(csm.getSpeed());
}
}
SpeedMeter类里提供了速度表的通用算法,但一些具体的实现细节则推迟到其子类CarSpeedMeter类中实现。这也是一种典型的模板设计。
模板模式在面向对象的软件中很常用,其原理简单,实现也很简单。下面是使用模板模式的一些简单规则。
- 抽象父类可以只定义需要使用的某些方法,把不能实现的部分抽象成抽象方法,留给其子类去实现。
- 父类中可能包含需要调用其他系列方法的方法,这些被调方法既可以由父类实现,也可以由其子类实现。父类里提供的方法只是定义了一个通用算法,其实现也许并不完全由自身实现,而必须依赖于其子类的辅助。
Java9改进的接口
接口的概念
接口是从多个相似类中抽象出来的规范,接口不提供任何实现。接口体现的是规范和实现分离的设计哲学。
让规范和实现分离正是接口的好处,让软件系统的各组件之间面对接口耦合,是一种松耦合的设计。
软件系统的各模块之间也应该采用这种面向接口的耦合,从而尽量降低各模块之间的耦合,为系统提供更好的可拓展性和可维护性。
Java9中接口的定义
[修饰符] interface 接口名 extends 父接口1,父接口2...{
零个到多个常量定义...
零个到多个抽象方法定义...
零个到多个内部类、接口、枚举定义...
零个到多个私有方法、默认方法或类方法定义...
}
- 修饰符有public或者省略,如果省略了public访问控制符,则默认采用包权限访问控制符,即只有在相同包结构下才可以访问该接口。
- 接口名只要是合法的标识符即可
- 一个接口可以有多个父接口,但接口只能继承接口,不能继承类。
在上面语法定义中,只有在Java8以上的版本中才允许在接口中定义默认方法、类方法。
由于接口定义的是一种规范,因此接口里不能包含构造器和初始化块定义。接口里可以包含成员变量(只能是静态常量)、方法(只能是抽象实例方法、类方法、默认方法或私有方法)、内部类(包括内部接口、枚举)定义。
对比接口和类的定义方法,不难发现接口的成员比类里的成员少了两种,而且接口里的成员变量只能是静态常量,接口里的方法只能是抽象方法、类方法、默认方法或私有方法。
前面已经说过了,接口里定义的是多个共同的公共行为规范,因此接口里的常量、方法、内部类和内部枚举都是public访问权限。定义接口成员时,可以省略访问控制修饰符,如果指定控制修饰符,则只能使用public访问控制修饰符。
Java9为接口增加了一种新的私有方法,其实私有方法的主要作用就是作为工具方法,为接口中的默认方法或类方法提供支持。私有方法可以拥有方法体,但私有方法不能使用default修饰。私有方法可以使用static修饰,也就是说,私有方法既可是类方法,也可是实例方法。
对于接口里定义的静态常量而言,它们是接口相关的,因此系统会自动为这些成员变量增加static和final修饰符。也就是说,在接口中定义成员变量时,不管是否使用public static final 修饰符,接口里的成员变量总是使用这三个修饰符来修饰。而且接口里没有构造器和初始化块,因此接口里定义的成员变量只能在定义时指定默认值。
接口里定义的方法只能是抽象方法、类方法、默认方法或私有方法,因此如果不是定义默认方法、类方法或私有方法,系统将自动为普通方法增加abstract修饰符;定义接口里的普通方法时不管是否使用public abstract 修饰符,接口里的普通方法总是使用public abstract 来修饰。接口里的普通方法不能有方法实现(方法体);但类方法、默认方法、私有方法都必须有方法实现(方法体)。
接口里定义的内部类、内部接口、内部枚举默认都采用public static两个修饰符,不管定义时是否指定这两个修饰符,系统都会自动使用public static对它们进行修饰。
interface Output {
int MAX_CACHE_LINE = 50;
void out();
void getData(String msg);
default void print(String... msgs){
for (var msg:msgs){
System.out.println(msg);
}
}
default void test(){
System.out.println("默认的test()方法");
}
static String staticTest(){
return "接口里的类方法";
}
private void foo(){
System.out.println("foo私有方法");
}
private static void bar(){
System.out.println("bar私有静态方法");
}
}
从Java8开始,在接口里允许定义方法,默认方法必须使用default修饰,该方法不能使用static修饰,无论程序是否指定,默认方法总是使用public修饰——如果开发者没有指定public,系统会自动为默认方法添加public修饰符。由于默认方法并没有static修饰,因此不能直接使用接口来调用默认方法,需要使用接口的实现类的实例来调用这些默认方法。
接口的默认方法其实就是实例方法,但由于早期Java的设计是:接口中的实例方法不能有方法体;Java8也不能直接"推倒"以前的规则,因此只好重定义一个所谓的"默认方法",默认方法就是有方法体的实例方法。
从Java8开始,在接口里允许定义类方法,类方法必须使用static修饰,该方法不能使用default修饰,无论程序是否指定,类方法总是使用public修饰——如果开发者没有指定public ,系统会自动为类方法添加public修饰符。类方法可以直接使用接口来调用。
Java9增加了带方法体的私有方法,这也是Java8埋下的伏笔:Java8允许在接口中定义带方法体的默认方法和类方法——这样势必会引发一个问题,当两个默认方法(或类方法)中包含一段相同的实现逻辑时,程序必然考虑将这段实现逻辑抽取成工具方法,而工具方法应该是被隐藏的,这就是Java9增加私有方法的必然性。
使用接口
接口不能用于创建实例,但接口可以用于声明引用类型变量。当使用接口来声明引用类型变量时,这个引用类型变量必须引用到其实现类的对象。除此之外,接口的主要用途就是被实现类实现。归纳起来,接口主要有如下用途:
- 定义变量,也可用于进行强制类型转换。
- 调用接口中定义的常量。
- 被其它类实现。
实现接口与继承父类相似,一样可以获得所实现接口里定义的常量(成员变量)、方法(包括抽象方法和默认方法)。
让类实现接口使用implements,一个类可以继承一个父类,并同时实现多个接口,implements部分必须放在extends部分之后。
一个类实现了一个或多个接口之后,这个类必须完全实现这些接口里所定义的全部抽象方法(也就是重写这些抽象方法);否则,该类将保留从父接口那里继承到的抽象方法,该类也必须定义成抽象类。
一个类实现某个接口时,该类将会获得接口中定义的常量(成员变量)、方法等,因此可以把实现接口理解为一种特殊的继承,相当于实现类继承了一个彻底抽象的类(相等于除默认方法外,所有方法都是抽象方法的类)。
下面看一个实现接口的类。
interface Output {
int MAX_CACHE_LINE = 50;
void out();
void getData(String msg);
default void print(String... msgs){
for (var msg:msgs){
System.out.println(msg);
}
}
default void test(){
System.out.println("默认的test()方法");
}
static String staticTest(){
return "接口里的类方法";
}
private void foo(){
System.out.println("foo私有方法");
}
private static void bar(){
System.out.println("bar私有静态方法");
}
}
interface Product{
int getProduceTime();
}
public class Printer implements Output,Product{
private String[] printData =new String[MAX_CACHE_LINE];
private int dataNum = 0;
@Override
public void out() {
while (dataNum > 0){
System.out.println("打印机打印:"+ printData[0]);
System.arraycopy(printData,1,printData,0,--dataNum);
}
}
@Override
public void getData(String msg) {
if (dataNum >= MAX_CACHE_LINE){
System.out.println("输出队列已满,添加失败");
}else{
printData[dataNum++] = msg;
}
}
@Override
public int getProduceTime() {
return 45;
}
public static void main(String[] args) {
Output o = new Printer();
o.getData("轻量级JAVA EE企业应用实战");
o.getData("疯狂JAVA讲义");
o.out();
o.getData("疯狂Android讲义");
o.getData("疯狂Ajax讲义");
o.out();
o.print("孙悟空","猪八戒","白骨精");
o.test();
Product p = new Printer();
System.out.println(p.getProduceTime());
//所有接口类型的引用变量都可直接赋给Object类型的变量
Object obj = p;
}
}
接口可以按照多态和abstract来进行理解,就可以很容易学会。
上面程序可以把Product类型的变量直接赋给Object类型变量,这是利用向上转型来实现的,因为编译器知道任何Java对象都必须是Object或其子类的实例,Product类型的对象也不例外(它必须是Product接口实现类的对象,该实现类肯定是Object的显示或隐式子类)。
接口和抽象类
接口和抽象类很像,它们都具备以下特征。
- 接口和抽象类都不能被实例化,它们都位于继承树的顶端,用于被其他类实现和继承。
- 接口和抽象类都可以包含抽象方法,实现接口或继承抽象类的普通子类都必须实现这些抽象方法。
接口和抽象类在用法上存在以下差别
- 接口里只能包含抽象方法、静态方法、默认方法和私有方法,不能为普通方法提供方法实现,抽象类则完全可以包含普通方法
- 接口里只能定义静态常量,不能定义普通成员变量;抽象类里则既可以定义普通成员变量,也可以定义静态常量
- 接口里不包含构造器;抽象类里可以包含构造器,抽象类里的构造器并不是用于创建对象,而是让其子类调用这些构造器来完成属于抽象类的初始化操作。
- 接口里不能包含初始化块;但抽象类则完全可以包含初始化块。
- 一个类最多只能有一个直接父类,包括抽象类:但一个类可以直接实现多个接口,通过实现多个接口可以弥补Java单继承的不足。
面向接口编程
简单工厂模式
有一个场景:假设程序中有个Computer类需要组合一个输出设备,现在有两个选择:直接让Computer类组合一个Printer,或者让Computer类组合一个Output,那么到底采用哪种方式更好呢?
假设让Computer组合一个Print对象,如果有一个系统需要重构,需要使用BetterPrint来代替Printer,这就需要打开Computer类源代码进行修改。如果系统中只有一个Computer类组合了Printer还好,但如果系统中有100个类组合了Printer,甚至100个、10000个……这是多么大的工作量啊!
为了避免这个问题,工厂模式建议让Computer类组合一个Output类型的对象,将Computer类与Printer类完全分离。Computer对象实际组合的是Printer对象还是BetterPrinter对象,对Computer而言完全透明。当Printer对象切换到BetterPrinter对象时,系统完全不受影响。下面是这个Computer类的定义代码。
public class Computer{
private Output out;
public Computer(Output out){
this.out = out;
}
//定义一个模拟获取字符串输入的方法
public void keyIn(String msg){
out.getData(msg);
}
//定义一个模拟打印的方法
public void print(){
out.out();
}
}
上面的Computer已经与Printer类分离,只是与Output接口耦合。Computer不再负责创建Output对象,系统提供一个Output工厂来负责生成Output对象。这个OutputFactory工厂类代码如下。
public class OutputFactory{
public Output getOutput(){
return new Printer();
}
public static void main(String[] args){
var of = new OutputFactory();
var c = new Computer(of.getOutput());
c.keyIn("轻量级JavaEE企业应用实战");
c.keyIn("疯狂Java讲义");
c.print();
}
}
上面介绍的就是一种被称为"简单工厂"的设计模式,所谓设计模式,就是对经常出现的软件设计问题的成熟解决方案。
命令模式
考虑这样一种场景:某个方法需要完成某一个行为,但这个行为的具体实现无法确定,必须等到执行该方法时才可以确定。具体一点:假设有个方法需要遍历某个数组的数组元素,但无法确定在遍历数组元素时如何处理这些元素,需要在调用该方法时指定具体的处理行为。
这个要求看起来有点奇怪:这个方法不仅需要普通数据可以变化,甚至还有方法体也需要变化,难道需要把"处理行为"作为一个参数传入该方法?
在某些编程语言(如Ruby等)中,确实允许传入一个代码块作为参数。通过Java8引入的Lambda表达式也可传入代码块作为参数。
对于这样一个需求,必须把"处理行为"作为参数传入该方法,这个"处理行为"用编程来实现就是一段代码。那如何把这段代码传入该方法呢?
可以考虑使用一个Command接口来定义一个方法,用这个方法来封装"处理行为"。下面是该Command接口的代码。
public interface Command {
//接口里定义的process方法用于封装"处理行为"
void process(int element);
}
public class ProcessArray {
public void process(int[]target,Command cmd){
for (var t : target){
cmd.process(t);
}
}
}
class PrintCommand implements Command {
@Override
public void process(int element) {
System.out.println("迭代输出目标数组的元素:" + element);
}
}
class SquareCommand implements Command {
@Override
public void process(int element) {
System.out.println("数组元素的平方:" + element * element);
}
}
public class CommandTest {
public static void main(String[] args) {
var pa = new ProcessArray();
int [] target = {3,-4,6,4};
pa.process(target,new PrintCommand());
System.out.println("-----------");
pa.process(target,new SquareCommand());
}
}
内部类
把一个类放在另一个类的内部定义,这个定义在其他类内部的类就被称为内部类(有的地方也叫嵌套类),包含内部类的类也被称为外部类(有的地方也叫宿主类)。Java从JDK1.1开始引入内部类,内部类主要有如下作用。
- 内部类提供了更好的封装,可以把内部类隐藏在外部类之内,不允许同一个包中的其他类访问该类。假设需要创建Cow类,Cow类需要组合一个CowLeg对象,CowLeg类只有在Cow类里才有效,离开了Cow类之后没有任何意义。在这种情况下,就可把CowLeg定义成Cow的内部类,不允许其他类访问CowLeg
- 内部类成员可以直接访问外部类的私有数据,因为内部类被当成其外部类成员,同一个类的成员之间可以互相访问。但外部类不能访问内部类的实现细节,例如内部类的成员变量。
- 匿名内部类适合用于创建那些仅需要一次使用的类。对于前面介绍的命令模式,当需要传入一个Command对象时,重新专门定义PrintCommand和SquareCommand两个实现类可能没有太大的意义,因为这两个实现类可能仅需要使用一次。在这种情况下,使用匿名内部类将更方便。
从语法角度来看,定义内部类与定义外部类的语法大致相同,内部类除需要定义在其他类里面之外,还存在如下两点区别。
- 内部类比外部类可以多使用三个修饰符:private、protected、static——外部类不可以使用这三个修饰符。
- 非静态内部类不能拥有静态成员。
非静态内部类
成员内部类分为两种:静态内部类和非静态内部类,使用static修饰的成员内部类是静态内部类,没有使用static修饰的成员内部类是非静态内部类。
因为内部类作为其外部类的成员,所以可以使用任意访问控制符如private、protected和public等修饰。
外部类的上一级程序单元是包,所以它只有2个作用域:同一个包内和任何位置,因此只需2种访问权限:包访问权限和公开访问权限。而内部类的上一级程序单元是外部类,它就具有4个作用域:同一个类、同一个包、父子类和任何位置,因此可以使用4种访问控制权限。
public class Cow {
private double weight;
//外部类的两个重载的构造器
public Cow(){}
public Cow(double weight){
this.weight = weight;
}
//定义一个非静态内部类
private class CowLeg{
//非静态内部类的两个实例变量
private double length;
private String color;
//非静态内部类的两个重载的构造器
public CowLeg(){}
public CowLeg(double length,String color){
this.length = length;
this.color = color;
}
//下面省略length、color的setter和getter方法
//...
//非静态内部类的实例方法
public void info(){
System.out.println("当前牛腿颜色是:" + color + ",高:" + length);
//直接访问外部类的private修饰的成员变量
System.out.println("本牛腿所在奶牛重:"+weight); //①
}
}
public void test(){
var c1 = new CowLeg(1.12,"黑白相间");
c1.info();
}
public static void main(String[] args) {
var cow = new Cow(378.9);
cow.test();
}
}
在外部类使用非静态内部类时,与平时使用普通类并没有太大的区别。
编译上面程序,可以看到在文件所在路径生成了两个class文件,一个Cow.class,另一个是Cow$CowLeg.class,
上面①表示,在非静态内部类里可以直接访问外部类的private实例变量。这是因为在非静态内部类对象里,保存了一个它所寄生的外部类对象的引用(当调用非静态内部类的实例方法时,必须有一个非静态内部类实例,非静态内部类实例必须寄生在外部类实例里)。
当在非静态内部类方法内访问某个变量时,系统优先在该方法内查找是否存在改名字的局部变量,如果存在就使用该变量;如果不存在,则到该方法所在内部类中查找是否存在该名字的成员变量,如果存在则使用该成员变量;如果不存在,则到该内部类所在的外部类中查找是否存在该名字的成员变量,如果存在则使用该成员变量;如果依然不存在,系统将出现编译错误:提示找不到该变量。
因此,如果外部类成员变量、内部类成员变量与内部类里方法的局部变量同名,则可通过使用this、外部类类名.this作为限定来区分。如下程序所示:
public class DiscernVariable {
private String prop = "外部类的实例变量";
private class InClass{
private String prop = "内部类的实例变量";
public void info(){
var prop = "局部变量";
System.out.println("外部类的实例变量值"+DiscernVariable.this.prop);
System.out.println("内部类的实例变量值"+this.prop);
//直接访问局部变量
System.out.println("局部变量的值"+prop);
}
}
public void test(){
var in = new InClass();
in.info();
}
public static void main(String[] args) {
new DiscernVariable().test();
}
}
非静态内部类的成员可以访问外部类的实例成员,但反过来就不成立了。如果外部类需要访问非静态内部类的实例成员,则必须显示创建非静态内部类对象来调用访问其实例成员。下面程序示范了这个规则。
public class Outer {
private int outProp = 9;
class Inner{
private int inProp = 5;
public void accessOuterProp(){
//非静态内部类可以直接访问外部类的private实例变量
System.out.println("外部类的OutProp的值:"+outProp);
}
}
public void accessInnerProp(){
//外部类不能直接访问非静态内部类的实例变量
//下面代码出现编译错误
//System.out.println("内部类的inProp值" + inProp);
}
public static void main(String[] args) {
//执行下面代码,只创建子外部类对象,还为创建内部类对象
var out = new Outer();
out.accessInnerProp();
}
}
根据静态成员不能访问非静态成员的规则,不允许在外部类的静态成员中直接使用非静态内部类。如下程序所示。
public class StaticTest {
private class In{}
public static void main(String[] args) {
//下面代码引发异常,因为静态成员(main()方法)无法访问非静态成员(In类)
//new In();
}
}
Java不允许在非静态内部类里定义静态成员。下面程序示范了非静态内部类里包含静态成员将引发编译错误。
public class InnerNoStatic {
private class InnerClass{
/*
下面三个静态声明都将引发如下编译错误:
非静态内部类不能有静态声明
*/
static{
System.out.println("=========");
}
private static int inProp;
private static void test();
}
}
非静态内部类里不能有静态方法、静态成员变量、静态初始化块,所以上面三个静态声明都会引发错误。
非静态内部类里不可能有静态初始化块,但可以包含普通初始化块。非静态内部类普通初始化块的作用与外部类初始化块的作用完全相同。
静态内部类
如果使用static来修饰一个内部类,则这个内部类就属于外部类本身,而不属于外部类的某个对象,因此使用static修饰的内部类被称为类内部类,有的地方也称为静态内部类。
使用static修饰可以将内部类变成外部类相关,而不是外部类实例相关。因此static关键字不可修饰外部类,但可修饰内部类。
静态内部类可以包含静态成员,也可以包含非静态成员。根据静态成员不能访问非静态成员的规则,静态内部类不能访问外部类的实例成员,只能访问外部类的类成员。即使是静态内部类的实例方法也不能访问外部类的实例成员,只能访问外部类的静态成员。下面程序就演示了这条规则。
public class StaticInnerClassTest {
private int prop1 = 5;
private static int prop2 = 9;
static class StaticInnerClass{
private static int age;
public void accessOuterProp(){
//下面代码出现错误
//静态内部类无法访问外部类的实例变量
//System.out.println(prop1);
//下面代码正常
System.out.println(prop2);
}
}
}
静态内部类是外部类的一个静态成员,因此外部类的所有方法、所有初始化块中可以使用静态内部类来定义变量、创建对象等。
外部类依然不能直接访问静态内部类的成员,但可以使用静态内部类的类名作为调用者来访问静态内部类的类成员,也可以使用静态内部类对象作为调用者来访问静态内部类的实例成员。下面程序示范了这条规则。
public class AccessStaticInnerClass {
static class StaticInnerClass{
private static int prop1 = 5;
private int prop2 = 9;
}
public void accessInnerProp(){
//System.out.println(prop1);
//上面代码出现错误,应改为如下形式
//通过类名访问静态内部类的类成员
System.out.println(StaticInnerClass.prop1);
//System.out.println(prop2);
//上面代码出现错误,应改为如下形式
//通过实例访问静态内部类的实例成员
System.out.println(new StaticInnerClass().prop2);
}
}
除此之外,Java还允许在接口里定义内部类,接口里定义的内部类默认使用public static修饰,也就是说,接口内部类只能是静态内部类。
如果为接口内部类指定访问控制符,则只能指定public访问控制符;如果定义接口内部类时忽略访问控制符,则该内部类默认是public访问控制权限。
接口中还能定义内部接口……
使用内部类
在外部类内部使用内部类
在外部类内部使用内部类时,与平时使用普通类没什么太大的区别,唯一一个区别是:不要在外部类的静态成员(包括静态方法和静态初始化块)中使用非静态内部类,因为静态成员不能访问非静态成员。
在外部类内部定义内部类的子类与平常定义子类也没有太大的区别
在外部类以外使用非静态内部类
如果希望在外部类以外的地方访问内部类(包括静态和非静态两种),则内部类不能使用private访问控制权限,private修饰的内部类只能在外部类内部使用。对于使用其他访问控制符修饰的内部类,则能在访问控制符对应的访问权限内使用。
- 省略访问控制符的内部类,只能被与外部类处于同一个包中的其他类所访问。
- 使用protected修饰的内部类,可被与外部类处于同一个包中的其他类和外部类的子类所访问。
- 使用public修饰的内部类,可以在任何地方被访问。
由于非静态内部类的对象必须寄生在外部类的对象里,因此创建非静态内部类对象之前,必须先创建其外部类对象。
public class CreateInnerInstance {
public static void main(String[] args) {
Out.In in = new Out().new In("测试信息");
//上面可以改成下面三行代码
Out.In in;
Out out = new Out();
in = out.new In("测试信息");
}
}
从代码可以看出来,非静态内部类的构造器必须使用外部类对象来调用
如果需要在外部类以外的地方创建非静态内部类的子类,则要注意规则:非静态内部类的构造器必须使用外部类对象来调用。
当创建一个子类时,子类构造器总会调用父类的构造器,因此在创建非静态内部类的子类时,必须保证让子类构造器可以调用非静态内部类的构造器,调用非静态内部类的构造器时,必须存在一个外部类对象。下面程序定义了一个子类继承了Out类的非静态内部类In类。
public class SubClass extends Out.In{
public SubClass(Out out) {
out.super("hello");
}
}
非静态内部类的子类不一定是内部类,它可以是一个外部类。但非静态内部类的子类实例一样需要保留一个引用,该引用指向其父类所在外部类的对象。也就是说,如果有一个内部类子类的对象存在,则一定存在一个与之对应的外部类对象。
在外部类以外使用静态内部类
因为静态内部类是外部类类相关的,因此创建静态内部类对象时无需创建外部类对象。在外部类以外的地方创建静态内部类实例的语法如下:
new OuterClass.InnerConstructor()
下面程序示范了如何在外部类以外的地方创建静态内部类的实例。
class StaticOut{
static class StaticIn{
public StaticIn(){
System.out.println("静态内部类的构造器");
}
}
}
public class CreateStaticInnerInstance {
public static void main(String[] args) {
StaticOut.StaticIn in = new StaticOut.StaticIn();
/*
上面代码可改为如下两行代码
使用OuterClass.InnerClass的形式定义内部类变量
StaticOut.StaticIn in;
通过new来调用内部类构造器创建静态内部类实例
in = new StaticOut.StaticIn();
*/
}
}
不管是静态内部类还是非静态内部类,它们声明变量的语法完全一样。区别只是在创建内部类对象时,静态内部类只需使用外部类即可调用构造器,而非静态内部类必须使用外部类对象来调用构造器。
因为调用静态内部类的构造器时无须使用外部类对象,所以创建静态内部类的子类也比较简单,下面代码就为静态内部类StaticIn类定义了一个空的子类。
public class StaticSubClass extends StaticOut.StaticIn{}
相比之下,使用静态内部类比使用费静态内部类要简单很多,只要把外部类当成静态内部类的包空间即可。因此当程序需要使用内部类时,应该优先考虑使用静态内部类
- [ ] 既然内部类是外部类的成员,那么是否可以为外部类定义子类,在子类里再定义一个内部类来重写父类的内部类?
- [ ] 不可以,内部类的类名不再简单由内部类的类名组成,它实际上还把外部类的类名作为一个命名空间,作为内部类类名的限制。因此子类中的内部类和父类中的内部类不可能完全重名,即使二者所包含的内部类的类名相同,但因为它们所处的外部类空间不同,所以它们不可能完全重名,也就不可能重写。
局部内部类
如果把一个内部类放在方法里定义,则这个内部类就是一个局部内部类,局部内部类仅在该方法里有效。由于局部内部类不能在外部类的方法以外的地方使用,因此局部内部类也不能使用访问控制符和static修饰符修饰。
对于局部成员而言,不管是局部变量还是局部内部类,它们的上一级成员单元都是方法,而不是类,使用static修饰它们没有任何意义。因此,所有的局部成员都不能使用static修饰。不仅如此,因为局部成员的作用域是所在方法,其他程序单元永远也不可能访问另一个方法中的局部成员,所以所有的局部成员都不能使用访问控制符修饰。
public class LocalInnerClass {
public static void main(String[] args) {
class InnerBase {
int a;
}
class InnerSub extends InnerBase {
int b;
}
var is = new InnerSub();
is.a = 5;
is.b = 8;
System.out.println("InnerSub对象的a和b实例变量是:" + is.a + "," + is.b);
}
}
编译上面程序,看到生成了三个class文件:LocalInnerClass.class、LocalInnerClass$1InnerBase.class和LocalInnerClass$1InnerSub.class,这表明局部内部类的class文件总是遵循如下命名格式:OuterClass$NInnerClass.class。注意到局部内部类的class文件比成员内部类的class文件的文件名多了一个数字,这是因为同一个类里不可能出现两个同名的成员内部类,而同一个类里则有可能有两个以上同名的局部内部类(处于不同方法中),所以Java为局部内部类的class文件名中增加了一个数字,用于区分。
局部内部类是一个非常"鸡肋"的语法,实际开发中很少使用,狗都不用
匿名内部类
匿名内部类适合创建那种只需要一次使用的类,匿名内部类的语法比较奇怪,创建匿名内部类时会立即创建一个该类的实例,这个类定义立即定义,匿名内部类不能重复使用。
定义匿名内部类的格式如下:
new 实现接口() | 父类构造器(实参列表){
//匿名内部类的类体部分
}
从上面定义可以看出,匿名内部类必须继承一个父类,或实现一个接口,但最多只能继承一个父类,或实现一个接口。
关于匿名内部类还有两条规则:
- 匿名内部类不能是抽象类,因为系统在创建匿名内部类时,会立即创建匿名内部类的对象。因此不允许将匿名内部类定义成抽象类。
- 匿名内部类不能定义构造器。由于匿名内部类没有类名,所以无法定义构造器,但匿名内部类可以定义初始化块,可以通过实例初始化块来完成构造器需要完成的事情。
最常用的创建匿名内部类的方式是需要创建某个接口类型的对象
interface Product{
double getPrice();
String getName();
}
public class AnonymousTest {
public void test(Product p){
System.out.println("购买了一个" + p.getName() + ",花掉了" + p.getPrice());
}
public static void main(String[] args) {
var ta = new AnonymousTest();
ta.test(new Product() {
@Override
public double getPrice() {
return 567.8;
}
@Override
public String getName() {
return "AGP显卡";
}
});
}
}
由于匿名内部类不能是抽象类,所以匿名内部类必须实现它的抽象父类或者接口里包含的所有抽象方法。
对于上面创建Product实现类对象的代码,可以拆分成如下代码。
interface Product{
double getPrice();
String getName();
}
class AnonymousProduct implements Product{
@Override
public double getPrice() {
return 567.8;
}
@Override
public String getName() {
return "AGP显卡";
}
}
public class AnonymousTest {
public void test(Product p){
System.out.println("购买了一个" + p.getName() + ",花掉了" + p.getPrice());
}
public static void main(String[] args) {
var ta = new AnonymousTest();
ta.test(new AnonymousProduct());
}
}
当通过实现接口来创建匿名内部类时,匿名内部类不能显示地定义构造器,因此匿名内部类只有一个隐式的无参数构造器,故new接口名后的括号里不能传入参数值。
但如果通过继承父类来创建匿名内部类时,匿名内部类将拥有和父类相似的构造器,此处的相似指的是拥有相同的形参列表。
abstract class Device{
private String name;
public abstract double getPrice();
public Device(){}
public Device(String name){
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
public class AnonymousInner {
public void test(Device d){
System.out.println("购买了一个" + d.getName());
}
public static void main(String[] args) {
var ai = new AnonymousInner();
//调用有参数的构造器创建Device匿名实现类的对象
ai.test(new Device("电子示波器"){
public double getPrice() {
return 0;
}
});
//调用无参数的构造器创建Device匿名实现类的对象
var d = new Device(){
//初始化类
{
System.out.println("匿名内部类的初始化块...");
}
@Override
public double getPrice() {
return 56.2;
}
@Override
public String getName() {
return "键盘";
}
};
ai.test(d);
}
}
在Java8之前,Java要求被局部内部类、匿名内部类访问的局部变量必须使用final修饰,从Java8开始这个限制被取消了,Java8更加智能:如果局部变量被匿名内部类访问,那么该局部变量相当于自动使用了final修饰。例如如下程序。
interface A{
void test();
}
public class ATest {
public static void main(String[] args) {
int age = 8;
var a = new A(){
public void test(){
System.out.println(age);
//下面代码报错
//age=2;
}
};
a.test();
}
}
Java8以后版本的JDK将这个功能称为"effectively final",它的意思是对于被匿名内部类访问的局部变量,可以用final修饰,也可以不用final修饰,但必须按照有final修饰的方式来用——也就是一次赋值后,以后不能重新赋值。
总结
Java基础部分就告一段落了,系统的把数据类型、对象、接口、抽象等等全部过了一遍,还有很多Lambda、反射、注解以及其他内容就不写在本章博客里了,该博客已经过长了,近乎4万字,再写显得有点臃肿了。宣布本篇博客,完结散花!
[^现在是2022-03-09 00:00:00]: